
基于网络编码的多信源组播通信系统,包括源代码,原理图等(二)
的填充长度:因为不同数据源的数据包的长度可能不一样,为了便于编码计算,将它们前位补0使得长度一致。由于一个典型的以太网数据包的长度在500~1500字节之间,所以填充长度不超过1000字节。另外,我们还要考虑MAC层的最大传送单元(MTU)的限制,即编码后的MAC帧的长度不能超过1518字节。由此可以计算出,被编码的数据包的最大长度是1499字节
本文引用地址://m.amcfsurvey.com/article/201612/326828.htm⑥编码系数:即随机选择的编码矢量的系数,是在一个GF256的有限域中随机选择。
⑦代的编号:即被编码的数据包的代的编号,是按照顺序产生的编号,目的是方便解码。
⑧包的信源号:4位,对进入编码路由器的数据包的信源进行编号,其目的是为了方便解码,在我们目前的体系中,最多允许8个数据包同时被编码。注意:当信源数少于8个时,例如有3个,则分别将对应的数据包的信源号分别填为0000,0001,0010,其余的都填写为1111。
2.4.5 转发(组播)路由器R工作流程
在实际的应用中,R应该是具有组播功能的路由器,即可以运行网际组播管理协议IGMP和多播路由选择协议DVMRP等,从而它可以知道网络的局部的拓扑和满足组播成员的要求。为了初期容易实现,我们将其功能简化为转发功能(即广播功能)。
2.4.6数据包的解码
(1) 高速缓存和CAM的使用
数据包的解码由DC解码路由器完成。每个解码路由器DC有三个输入通道,分别连接到R0,R1,R2其解码的策略是:我们先在DC中开辟三块不同的高速缓存(DRAM)和与之分别对应的3个CAM,它们分别对应于R0、R1、R2,缓存和CAM的大小为代的编号的大小,即 =1024,在这三个缓存中存放按照顺序接收到的数据。根据前面的数据处理过程,显然,对应于每个缓存中的数据,虽然有的是真正编码后的数据包,有的只是在IP数据包前增加了一个包头,但我们都可以认为是NCP数据包。在将数据存入高速缓存的同时,提取NCP数据包头中的信源号和代的编号,将它们存入到内容可寻址存储器CAM(content addressable memory),则CAM的输出即为对应数据在高速缓存的地址。
使用CAM的原因是:由于经过编码,以及网络环境非理想,解码路由器收到的encoded packet可能是乱序的。因此考虑使用CAM做检索链接,以便快速寻址当前解码所需要的packet。 (2) 解码顺序
根据实际情况的考虑,目前有两种解码的顺序,一种情况是按照信源号和代的编号的顺序进行解码,第二种情况是按照缓存及其缓存地址的顺序来解码。
在已知网络拓扑的情况下,我们按照信源号和代的编号的顺序来进行解码,即对于信源采用轮询策略,对于内部代的编号采用小数优先策略。例如,在我们的拓扑图中,解码顺序是:S(1,1),S(2,1),S(3,1)→S(1,2),S(2,2),S(3,2)→……S(1,n),S(2,n),S(3,n)……。
在未知网络拓扑的情况下,我们按照高速缓存的地址顺序来进行解码,即先对高速缓存采用轮询策略,对每个缓存中,采用地址由小到大的顺序进行解码,如图2.4-7所示,进行解码的顺序是PZ1
→PX1→ PY1→ PZ2→ PX2→PY2→PZ3……
高速缓存1 高速缓存2 高速缓存3
地址 数据包 地址 数据包 地址 数据
01 PZ1 01 PX1 01 PY1
02 PZ2 02 PX2 02 PY2
03 PZ3 03 PX3 03 PY3
04 …… 04 …… 04 ……
……
图2.4-7 按照高速缓存的地址顺序来进行解码
上面的两种解码方式各有优点:在一般情况下,按照信源号和代的编号的顺序来进行解码可获得较高的解码速率,但在网络环境恶化的情况下,其丢包率(无法解码的概率)会比第2中方案高一些。由于在我们已有的网络环境一般较好,为了体现网络编码的传输的高效性,我们按照第1种顺序进行解码。
(3) 解码流程
为了避免高速缓存的写数据溢出,我们将设置二级缓存,二级缓存也有3个,可用SRAM构造,将SRAM分为3块地址上独立的区域,每个SRAM 大小为256×1800bytes,分别对应不同的信源,我们将解码后的数据,根据其代的编号,分别暂存在对应SRAM的对应地址上。例如,将S(1,1)存储在SRAM1的第1个地址空间,S(2,4)则存储在SRAM2的第4个地址空间。每个RAM各有1个读、写指针,可以同时按顺序读写数据,按照地址由小到大的顺序读出的数据被发送到输出队列中。
如图2.4-8所示为数据包的解码过程,每个告诉缓存各有1个读、写指针,在解码过程中,读取缓存是按照解码的顺序进行的,而在写缓存是按地址顺序写的。
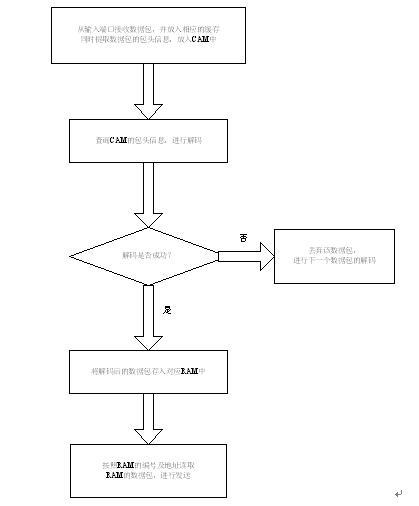
图2.4-8:数据包解码流程
(4) 解码策略与方法
我们按照信源号和代的编号的顺序来进行解码,即对于信源采用轮询策略,对于内部代的编号采用小数优先策略。例如,在我们的拓扑图中,解码顺序是:S(1,1),S(2,1),S(3,1)→S(1,2),S(2,2),S(3,2)→……S(1,n), S(2,n), S(3,n)……
假定我们按照上述顺序准备解码S(1,x),解码程序如图9:
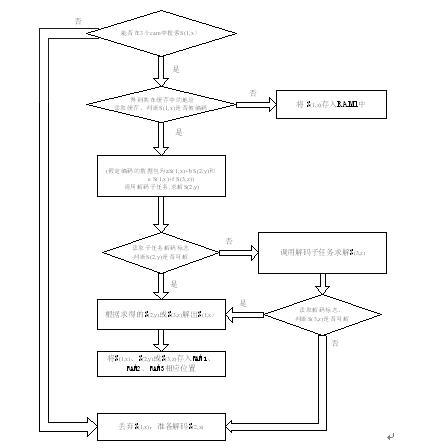
图2.4-9 数据包S(1,x)的解码过程
无法求解一个数据包的原因可能是:该数据包由于延迟或者丢失,在CAM中搜寻不到,再有就是线性相关,无法解出来。在我们的系统中,由于其拓扑的特殊性,没有线性相关的情况,因此无法解码的情况只发生在解码因子丢失的情况下。
解码子任务:解码子任务的输入是包头信息,由调用它的程序给出,输出有两个变量:解码后的数据包和解码标志,解码标志告诉调用它的程序是否可以解码,我们假定现在要对S(i,j)解码,子任务流程如图2.4-10:
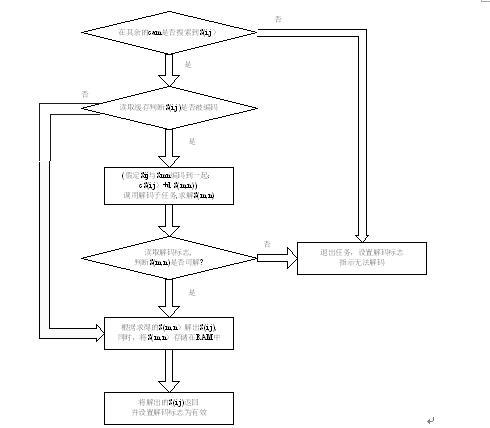
图2.4-10:解码子任务流程 (5) 解码后数据包暂存SRAM的读写策略
我们将解码后的数据包暂存在SRAM中等待发送,每个信源对应一个SRAM区域,同一个信源的解码后的人数据包存储在同一个RAM中,存储地址为该包的代的编号。每个RAM各有一个读指针,写数据按照RAM的地址大小顺序写入。读数据时按照信源编号和代的大小读取。由于发送速率一般会高于解码速率,因此RAM不用很大,暂定为256×1800。
每读取一个数据后,指针加1,若读取某个SRAM时无数据(可能是延迟或丢失造成),则不用等待,直接进行下一个SRAM的读取,3次轮询之后还没有到达,则强行加读指针加1,读取下一个数据包。如图2.4-11所示为SRAM的读写操作。
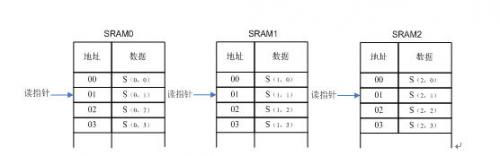
图2.4-11 二级缓存SRAM的读写操作
(6)举例说明
为了更清楚地显示整个解码的操作过程,我们以DC3为例,图2.4-12显示的是DC3的3个高速缓存和CAM,解码过程如下
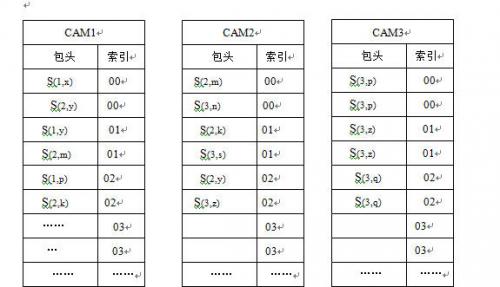
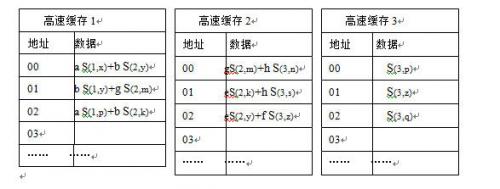
图2.4-12 数据包S(1,x)解码过程
数据包S(1,x)解码过程如下:
先将S(1,x)的包头3个CAM中搜索,在CAM1中得到索引为00,我们利用该索引得到S(1,x)在高速缓存1的地址为00,从高速缓存1读取数据,得到a S(1,x)+b S(2,y),为了求解S(1,x)我们调用解码子任务先求解S(2,y),为了防止出现死循环,解码子任务只在CAM2和CAM3中搜寻S(2,y),在CAM2中得到地址为02,于是读取高速缓存2的02地址数据,得到eS(2,y)+f S(3,z),于是再调用子任务求解S(3,z),在CAM3中搜索S(3,z)后解出S(3,z), 于是可以解出S(2,y),最后再解出S(1,x),同时,分别将S(3,z)、 S(2,y) 、S(1,x)存入SRAM3,SRAM2,SRAM1相应的地址中。
2.5 系统软硬件接口及相关软件功能
在系统中,并非只有硬件逻辑在不同的模块之间处理数据包,而且还有相应的软件和控制程序。如图2.5-1所示,是数据包在系统中的通道与处理流程。数据在系统中的通道分为data bus和register bus,data bus主要进行数据的硬件处理,register bus则是软硬件的接口。在数据传输的每个阶段对软件应该是可控的、透明的,这些软件在更高层次上执行更复杂的算法和协议,或者处理一些异常情况,同时,对于系统开发人员,也应该是可控的,因为开发人员往往需要配置和调试硬件。使用通用的寄存器接口就可以使数据处理对软件透明化,这是靠映射内部的硬件寄存器来完成的,即所谓的存储映射技术。对于软件来讲,映射寄存器相当于一个I/O接口,它可以由软件访问和修改。
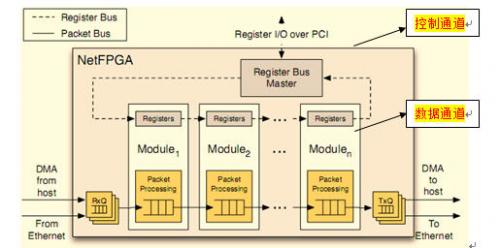
图2.5-1:系统中的register bus 和data bus
Register bus中每个模块的register连接在一起,组成一个信息环路。这些register块中存储了数据处理在每个


评论