
有图有真相:深度拆解谷歌TPU3.0,新一代AI协同处理器
通过将服务器主板集成到云 TPU 机架中,谷歌可以用相同的机架配置使机架数量增加一倍。在一个机架上标准化配置必然有助于降低硬件部署的成本和复杂性。
本文引用地址://m.amcfsurvey.com/article/201805/380204.htm
电脑架:TPUv2(左)和 TPUv3(右)
但是,为了实现更高的密度,谷歌必须从 4U 云 TPU 外形规格转变为 2U 高密度外形规格。其数据中心温度很高(公布的数据在 80°F 到 95°F 之间),因此 TPUv2 风冷散热器必须很大。谷歌使用开放式机架,所以利用风来冷却密集外形规格的热插槽变得非常昂贵,使得水冷成为可行的替代方案。特别是对于像深度学习这样的高价值服务。
将服务器主板转移到 TPUv3 机架中还会缩短连接电缆,因此我们一般认为谷歌节省了大量电缆成本,并除去了 TPUv2 Pod 服务器机架中的闲置空间。

谷歌没有展示主板与机架水互连的照片。
云 TPU
但是,它确实显示了 TPUv3 云 TPU 的两张照片。TPUv3 云 TPU 具有与 TPUv2 云 TPU 相似的布局。明显的变化是水冷却的增加。主板电源接头的背面看起来相同。但是,主板前面还有四个附加连接器。照片正面(左)的两个银色大正方形是由四个连接器组成的集群。

TPUv3 主板(左上),TPUv2 主板(左下)和 TPUv3 主板特写(右)
谷歌没有提及其他连接器。我们认为最有可能的解释是 Google 为环形超网格(hyper-mesh)添加了一个维度,也就是从 2D 环形超网格到 3D 环形超网格。
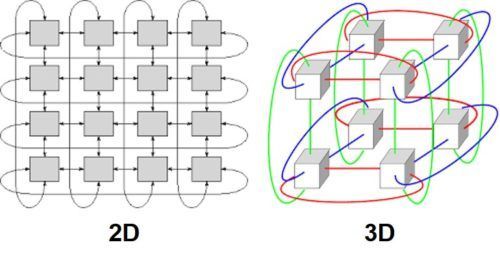
环形超网格互连图:2D(左)和 3D(右)
去年,我们推测了几种类型的互连,并将其称为错误的互连——谷歌使用 32 条有线 PCI-Express 3.0(每条链路 28GB / s)将服务器连接到云 TPU 上。我们认为,谷歌不太可能增加服务器主板和云 TPU 之间的带宽,因为 PCI-Express 带宽和延迟可能不是什么重要的性能限制因素。
虽然互连拓扑将有助于深度学习任务在 pod 中更好地扩展,但它不会对原始的理论性能带来贡献。
TPU 芯片
现在,我们要深入到芯片层面来回答以下问题:「剩下的 2 倍性能改进来自哪里?」谷歌概括其 TPUv2 核心为:
有两个矩阵单元(MXU)每个 MXU 都有 8GB 的专用高带宽内存(HBM)每个 MXU 的原始峰值吞吐量为 22.5 万亿次但是 MXU 不使用标准浮点格式来实现其浮点吞吐量谷歌创造了自己的内部浮点格式,称为「bfloat」,意为「大脑浮点(brain floating point)」(在谷歌大脑之后)。Bfloat 格式使用 8 位指数和 7 位尾数,而不是 IEEE 标准 FP16 的 5 位指数和 10 位尾数。Bfloat 可以表示从~1e-38 到~3e38 的值,其动态范围比 IEEE 的 FP16 宽几个数量级。谷歌之所以创造 bfloat 格式,是因为它发现在 IEEE 标准 FP16 的训练中需要数据科学专家,以确保数据保持在 FP16 较为有限的范围内。
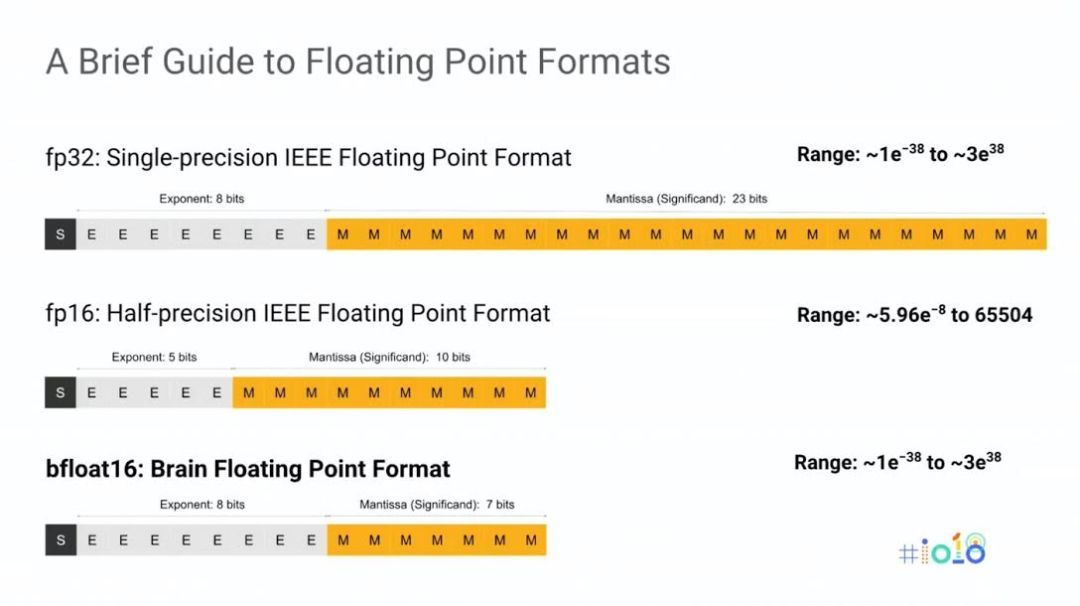
我们相信谷歌已经在 MXU 内部实现了硬件格式转换,真正消除了转换延迟和软件开发难题。从 FP16 到 bfloat 的格式转换看起来像是直接把精度截断到较小的尾数。将 FP16 转换为 FP32,然后再将 FP32 转换为 FP16 是已知的实践;可以使用相同的技术把格式从 FP32 转换成 bfloat,然后再从 bfloat 转换成 FP16 或 FP32。
谷歌声称,随着数据流通过 MXU 的收缩阵列,中间结果得到了「极大」的重复使用。
考虑到 MXU 的表现,我们相信谷歌不太可能在从 TPUv2 到 TPUv3 的转变中将 MXU 做出改变。更有可能的结果是,谷歌将把 TPUv3 的 MXU 数量增加一倍。
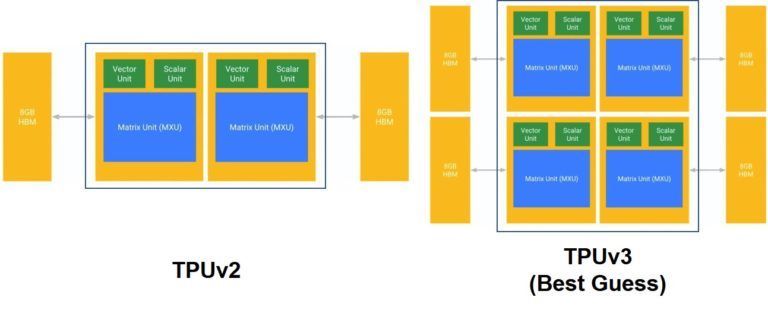
框图:TPUv2(左)和 TPUv3(右)
距离上次芯片发布只有一年,因此芯片设计节奏非常短,没有时间进行重要的架构开发。但是,足够将现有的 MXU 核心压缩为新的制造工艺、调整功耗和速度路径,然后做一点额外的平面规划工作,以在模具上冲压更多的 MXU 核心。下表包含了我们所掌握的少量硬信息,以及我们对谷歌 TPUv3 芯片发展方向的最佳估计。
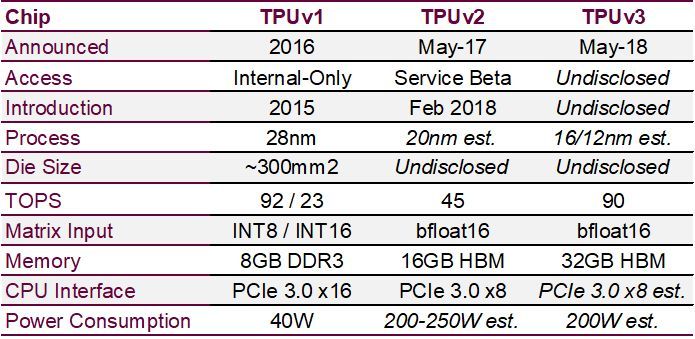
去年,我们估计 TPUv2 每个芯片需要消耗 200 瓦至 250 瓦。现在我们知道,每个包中还包含 16GB 的 HBM,其 MXU 和 HBM 之间的带宽为 2.4 TB /秒。
我们将坚持去年估计的 36 千瓦机架电源(一个 TPUv3pod 总共需要 288 千瓦)。如果假设每台双插槽服务器的功率为 400 瓦,我们会把每台 TPUv3 芯片的功率将向后降至 200 瓦左右,其中包括 32GB 的 HBM。如果这些芯片没有密集地封装在主板和机架上,或者被部署在较冷的数据中心,那它们可能不需要水冷。另一种选择可能是谷歌正在他们的新 TPUv3 集群中部署单插槽服务器。将服务器功率降至 250 瓦以下可能会为 TPUv3 提供足够的扩展空间,以达到 225 瓦。
假定最初 TPUv2 MXU 设计保守,随后 TPUv3 工艺收缩、HBM 变宽且更快,并且路径调整速度加快,则可以合理地期望每个核的性能在两代之间保持不变,而无需彻底地对 MXU 进行重新设计。
市场回顾
谷歌仍在部署 TPUv1 外接程序卡,用于推理任务,四个 TPUv1 用于一台服务器上。谷歌部署了 TPUv1 来加速网页搜索和其他大规模推理任务——如果你最近使用了谷歌搜索引擎,你可能已经使用了 TPUv1。
谷歌仅通过其测试云 TPU 实例提供 TPUv2 访问,并未预测何时通过服务级别协议供应可用产品。谷歌本周确实表示,它将在「今年年底」向客户提供 TPUv2 pod 服务,但尚不清楚这是否为一项产品服务。我们最大的猜测是,谷歌将继续等待,直到验证和调试完 TPUv3 pod,以便在全球范围内部署 TPU pod。谷歌内部正在使用 TPUv2 pod 进行一些训练任务。本周,谷歌没有就何时部署基于 TPUv3 芯片的任何功能或服务发表任何声明。我们认为,TPUv3 的发布旨在强调谷歌长期致力于控制自己内部生态的承诺,以加速其 TensorFlow 深度学习框架。
然而,我们认为 TPUv3 更多的应该算 TPUv2.5,而不是新一代芯片。大多数新硬件开发似乎都是围绕 TPUv3 芯片级别的系统展开的。






评论