
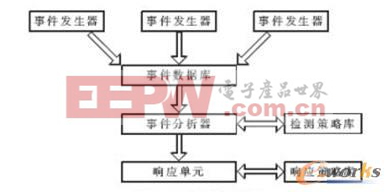
基于数据挖掘技术的入侵检测系统解决方案
特征提取器的工作过程可分为数据预处理和产生关联规则。
(1)数据预处理特征提取器的输入为日志记录.包含很多字段,但并非所有字段都适用于关联分析。在此仅选择和Snort规则相关的字段,如SrcIP,SrcPort,DstIP,DstPort,Protocol,Dsize,Flags和CID等。
(2)产生关联规则首先根据设定的支持度找出所有频繁项集,一般支持度设置得越低,产生的频繁项集就会越多;而设置得越高,产生的频繁项集就越少。接着由频繁项集产生关联规则,一般置信度设置得越低,产生的关联规则数目越多但准确度不高;反之置信度设置得越高。产生的关联规则数目越少但是准确度较高。
3.4系统模型特点
该系统在实际应用时,既可以事先存入已知入侵规则,以降低在开始操作时期的漏报率,也可以不需要预先的背景知识。虽然该系统有较强的自适应性,但在操作初期会有较高的误报率。因此该系统模型有如下特点:(1)利用数据挖掘技术进行入侵检测;(2)利用先进的挖掘算法,使操作接近实时;(3)具有自适应性,能根据当前的环境更新规则库;(4)不但可检测到已知的攻击,而且可检测到未知的攻击。
4系统测试
以Snort为例,在规则匹配方面扩展系统保持Snort的工作原理,实验分析具有代表性,分析攻击模式数据库大小与匹配时间的关系。
实验环境:IP地址为192.168.1.2的主机配置为PIV1.8G,内存512M,操作系统为WindowsXP;3台分机的IP地址分别为192.168.1.23,192.168.1.32,192.168.1.45。实验方法:随机通过TcpDump抓取一组网络数据包,通过该系统记录约20min传送来的数据包,3台分机分别对主机不同攻击类型的数据包进行测试。
异常分析器采用K-Means算法作为聚类分析算法,试验表明.误检率随阈值的增大而迅速增大,而随阈值的减小而逐渐减小。由于聚类半径R的增大会导致攻击数据包与正常数包被划分到同一个聚类,因此误检率必然会随着阈值的增大而增大。另一方面,当某一种新类型的攻击数据包数目达到阈值时,系统会将其判定为正常类,因此阈值越小必然导致误检率越高。当聚类半径R=6时,该系统比Snort原始版本检测的速度快,并且误检率也较低。
特征提取器采用关联分析的Apriori算法,置信度设置为100%,阈值设为1000,支持度50%,最后自动生成以下3条新的入侵检测规则:
alerttcp192.168.1.232450->192.168.1.280(msg:”poli-cy:externalnetattempttoaccess192。168。1。2”;classtype:at-temptesd-recon;)
alerttcp192.168.1.321850->192.168.1.221(msg:”poli-cy:extemalnetattempttoaccess192.168.1.2”;classtype:at-tempted-recon;)
alerttcp192.168.1.452678->192.168.1.21080(msg:”policy:extemalnetattempttoaccess192.168。1。2”;classtype:at-tempted-reeon;)
该试验结果说明经采用特征提取器对异常日志进行分析,系统挖掘出检测新类型攻击的规则,并具备检测新类型攻击的能力。
5结束语
提出一种基于数据挖掘的入侵检测系统模型,借助数据挖掘技术在处理大量数据特征提取方面的优势,可使入侵检测更加自动化,提高检测效率和检测准确度。基于数据挖掘的入侵检测己得到快速发展,但离投入实际使用还有距离,尚未具备完善的理论体系。因此,解决数据挖掘的入侵检测实时性、正确检测率、误警率等方面问题是当前的主要任务,及丰富和发展现有理论,完善入侵检测系统使其投入实际应用。





评论