
2016人工智能技术发展进程梳理

Intel人工智能布局
本文引用地址://m.amcfsurvey.com/article/201702/343473.htmIntel收购Nervana
8月9日,Intel宣布收购创业公司Nervana Systems。Nervana的IP和加速深度学习算法经验可帮助Intel在人工智能领域获得一席之地。
Nervana提供基于云的服务用于深度学习,使用独立开发的、使用汇编级别优化的、支持多GPU的Neon软件,在卷积计算时采用了Winograd算法,数据载入也做了很多优化。该公司宣称,训练模型时,Neon比使用最普遍的Caffe快2倍。不仅如此,Nervana准备推出深度学习定制芯片Nervana Engine,相比GPU在训练方面可以提升10倍性能。与Tesla P100类似,该芯片也利用16-bit半精度浮点计算单元和大容量高带宽内存(HBM,计划为32GB,是竞品P100的两倍),摒弃了大量深度学习不需要的通用计算单元。
在硬件基础上,Nervana于11月份推出了Intel Nervana Graph平台(简称ngraph)。该框架由三部分组成:一个用于创建计算图的API、用于处理常见深度学习工作流的前端API(目前支持TensorFlow和Neon)、用于在 CPU/GPU/Nervana Engine上编译执行计算图的转换器API。
与此同时宣布成立Intel Nervana人工智能委员会,加拿大蒙特利尔大学Yoshua Bengio教授担任创始会员。
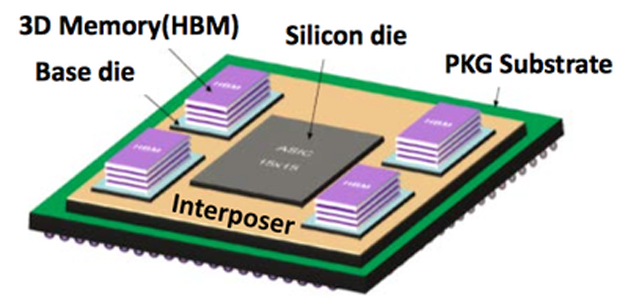
图7 Nervana Engine芯片架构
8月17日,在Intel开发者峰会(IDF)上,Intel透露了面向深度学习应用的新Xeon Phi处理器,名为Knights Mill(缩写为 KNM)。它不是Knights Landing和Knights Hill的竞品,而是定位在神经网络云服务中与NVIDIA Tesla GPU一较高下。
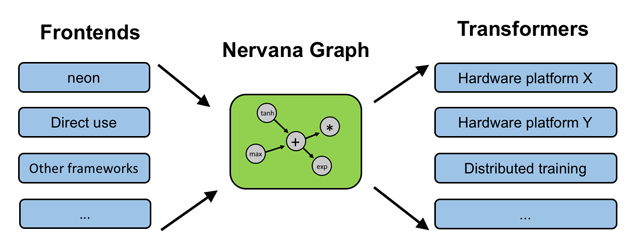
图8 ngraph框架
9月6日,Intel收购计算机视觉创业公司Movidius。
Movidius是人工智能芯片厂商,提供低能耗计算机视觉芯片组。Google眼镜内配置了Movidius计算机视觉芯片。Movidius芯片可以应用在可穿戴设备、无人机和机器人中,完成目标识别和深度测量等任务。除了Google之外Movidius与国内联想和大疆等公司签订了协议。Movidius的Myriad 2系列图形处理器已经被联想用来开发下一代虚拟现实产品。
9月8日,Intel FPGA技术大会(IFTD)杭州站宣布了Xeon-FPGA集成芯片项目。这是Intel并购Altera后最大的整合举动,Intel将推出CPU+FPGA架构的硬件平台,该平台预计于2017年量产,届时,一片Skylake架构的Xeon CPU和一片Stratix10的FPGA将“合二为一”,通过QPI Cache一致性互联使FPGA获得高带宽、低延迟的数据通路。在这种形态中,FPGA本身就成为了CPU的一部分,甚至CPU上的软件无需“感知”到FPGA的存在,直接调用mkl库就可以利用 FPGA来加速某些计算密集的任务。
Xeon-FPGA样机已经在世界七大云厂商(Amazon、Google、微软、Facebook、百度、阿里、腾讯)试用,用于加速各自业务热点和基础设施,包括机器学习、搜索算法、数据库、存储、压缩、加密、高速网络互连等。
除了上面CPU+FPGA集成的解决方案,Altera也有基于PCIe加速卡的解决方案。
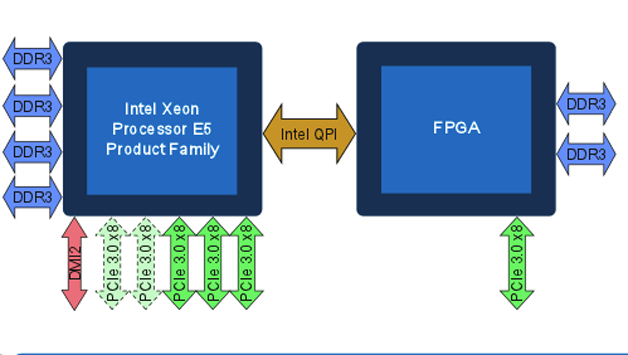
图9 Xeon-FPGA集成芯片架构
11月8日ISDF大会上宣布,预计明年将销售深度学习预测加速器(DLIA,Deep Learning Inference Accelerator)。该加速器为软硬件集成的解决方案,用于加速卷积神经网络的预测(即前向计算)。软件基于Intel MKL-DNN软件库和Caffe框架,便于二次开发,基于PCIe的FPGA加速卡提供硬件加速。该产品将直接同Google TPU、NVIDIA Tesla P4/M4展开竞争。
小结: Intel在人工智能领域的动作之大(All in AI),品类之全(面向训练、预测,面向服务器、嵌入式),涉猎之广(Xeon Phi,FPGA,ASIC)令人为之一振。冰冻三尺非一日之寒,AI硬件和上层软件的推广与普及还有很长一段路要走。
NVIDIA人工智能布局
NVIDIA财报显示,深度学习用户目前占据数据中心销售额一半,而HPC占三分之一,剩下的为虚拟化(例如虚拟桌面)。这也驱动NVIDIA在硬件架构和软件库方面不断加强深度学习性能,典型例子是在Maxwell处理器中最大化单精度性能,而在Pascal架构中增加了半精度运算单元。与HPC不同,深度学习软件能够利用较低精度实现较高吞吐。
Pascal架构
在4月5日GTC(GPU Technology Conference)2016大会上,NVIDIA发布了16nm FinFET制程超级核弹帕斯卡(Pascal)显卡,最让人惊叹的还是一款定位于深度学习的超级计算机DGX-1。DGX-1拥有8颗帕斯卡架构GP100核心的Tesla P100 GPU,以及7TB的SSD,两颗16核心的Xeon E5-2698 v3以及512GB的DDR4内存,半精度浮点处理能力170TFLOPS,功耗3.2kW。售价129000美元,现已面市。
9月13日,NVIDIA在GTC中国北京站发布了Tesla P4和P40。这两个处理器也基于最新的Pascal架构,是去年发布的M4和M40的升级版,包括了面向深度学习预测计算的功能单元,丢掉了64位双精度浮点计算单元,取而代之的是8-bit整数算法单元。详细参数如下。

图10 DGX-1外观
Tesla P4为半高半长卡,功耗只有50~75W,便于安装到已有的Web Server提供高效的预测服务。同时,P4包括一个视频解码引擎和两个视频编码引擎,对基于视频的预测服务更为适合。
Tesla P40与P4用途稍有不同,绝对性能高,适合训练+预测,使用GoogLeNet评估时相比上一代M40有8倍性能提升。
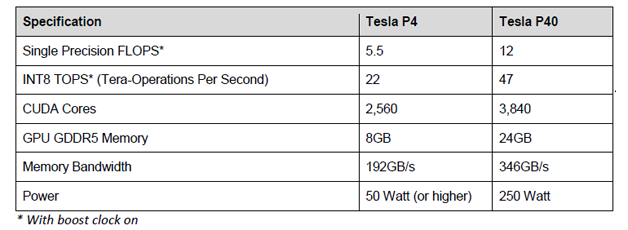
图11 Tesla P4/P40参数对比
Tesla P100仍然是最合适训练的GPU,自带NVLink多GPU快速互联接口和HBM2。这些特性是P40和P4不具备的,因为面向预测的GPU不需要这些。
Pascal家族从P100到P4,相对三年前的Kepler架构提速达到40~60倍。
在硬件之外,NVIDIA软件方面也不遗余力。
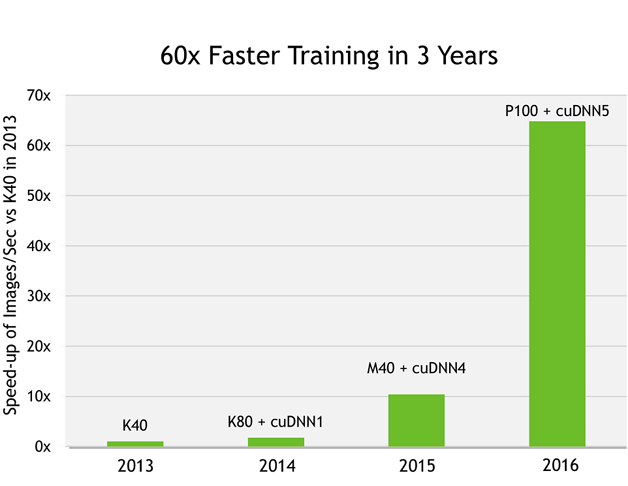
图12 NVIDIA Pascal架构软硬件加速情况
cuDNN
NVIDIA CUDA深度神经网络库(cuDNN)是一个GPU上的深度神经网络原语加速库。cuDNN提供高度优化的标准功能(例如卷积、下采样、归一化、激活层、LSTM的前向和后向计算)实现。目前cuDNN支持绝大多数广泛使用的深度学习框架如Caffe、TensorFlow、Theano、Torch和CNTK等。对使用频率高的计算,如VGG模型中的3x3卷积做了特别优化。支持Windows/Linux/MacOS系统,支持Pascal/Maxwell/Kepler硬件架构,支持嵌入式平台Tegra K1/X1。在Pascal架构上使用FP16实现,以减少内存占用并提升计算性能。
TensorRT
TensorRT是一个提供更快响应时间的神经网络预测引擎,适合深度学习应用产品上线部署。开发者可以使用TensorRT实现高效预测,利用INT8或FP16优化过的低精度计算,可以显著降低延迟。
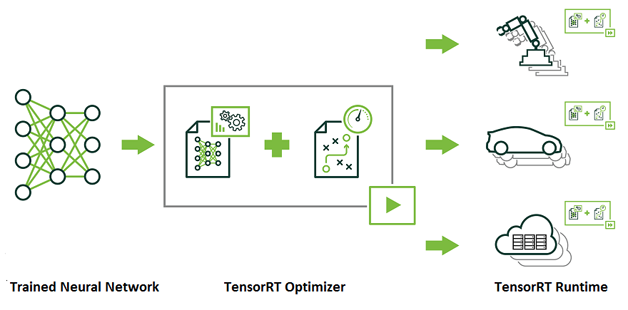
图13 TensorRT的使用方式
DeepStream SDK支持深度学习视频分析,在送入预测引擎之前做解码、预处理。
这两个软件库都是与Pascal GPU一起使用的。
小结: NVIDIA是最早在AI发力的硬件厂商,但从未停止在软件上的开发和探索,不断向上发展,蚕食、扩充自己在AI的地盘,目前已经涵盖服务器/嵌入式平台,面向多个专用领域(自动驾驶、医疗健康、超算),具备极强的爆发力(从今年NVIDIA股票也能看出这一点)。











评论