
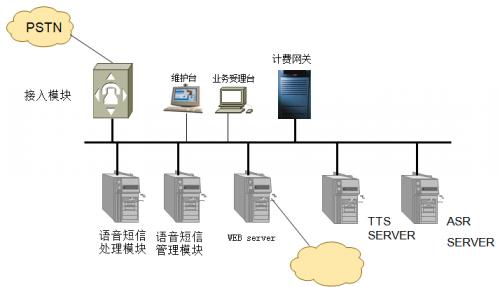
语音识别技术的研究与发展
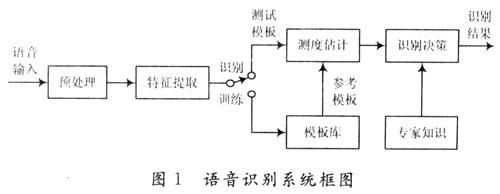
(2)特征提取模块:负责计算语音的声学参数,并进行特征的计算,以便提取出反映信号特征的关键特征参数用于后续处理。现在较常用的特征参数有线性预测(LPC)参数、线谱对(LSP)参数、LPCC、MFCC、ASCC、感觉加权的线性预测(PLP)参数、动态差分参数和高阶信号谱类特征等[1]。其中,Mel频率倒谱系数(MFCC)参数因其良好的抗噪性和鲁棒性而应用广泛。
(3)训练阶段:用户输入若干次训练语音,经过预处理和特征提取后得到特征矢量参数,建立或修改训练语音的参考模式库。
(4)识别阶段:将输入的语音提取特征矢量参数后与参考模式库中的模式进行相似性度量比较,并结合一定的判别规则和专家知识(如构词规则,语法规则等)得出最终的识别结果。
4语音识别的几种基本方法
当今语音识别技术的主流算法,主要有基于动态时间规整(DTW)算法、基于非参数模型的矢量量化(VQ)方法、基于参数模型的隐马尔可夫模型(HMM)的方法、基于人工神经网络(ANN)和支持向量机等语音识别方法。
4.1 动态时间规整(DTW)
DTW是把时间规整和距离测度计算结合起来的一种非线性规整技术,是较早的一种模式匹配和模型训练技术。该方法成功解决了语音信号特征参数序列比较时时长不等的难题,在孤立词语音识别中获得了良好性能。
4.2 矢量量化(VQ)
矢量量化是一种重要的信号压缩方法,主要适用于小词汇量、孤立词的语音识别中。其过程是:将语音信号波形的k个样点的每1帧,或有k个参数的每1参数帧,构成k维空间中的1个矢量,然后对矢量进行量化。量化时,将k维无限空间划分为M个区域边界,然后将输入矢量与这些边界进行比较,并被量化为“距离”最小的区域边界的中心矢量值。矢量量化器的设计就是从大量信号样本中训练出好的码书,从实际效果出发寻找到好的失真测度定义公式,设计出最佳的矢量量化系统,用最少的搜索和计算失真的运算量,实现最大可能的平均信噪比。
4.3 隐马尔可夫模型(HMM)
隐马尔可夫模型是20世纪70年代引入语音识别理论的,它的出现使得自然语音识别系统取得了实质性的突破。目前大多数大词汇量、连续语音的非特定人语音识别系统都是基于HMM模型的。
HMM是对语音信号的时间序列结构建立统计模型,将其看作一个数学上的双重随机过程:一个是用具有有限状态数的Markov链来模拟语音信号统计特性变化的隐含的随机过程,另一个是与Markov链的每一个状态相关联的观测序列的随机过程。前者通过后者表现出来,但前者的具体参数是不可测的。人的言语过程实际上就是一个双重随机过程,语音信号本身是一个可观测的时变序列,是由大脑根据语法知识和言语需要(不可观测的状态)发出的音素的参数流。HMM合理地模仿了这一过程,很好地描述了语音信号的整体非平稳性和局部平稳性,是较为理想的一种语音模型。
HMM模型可细分为离散隐马尔可夫模型(DHMM)和连续隐马尔可夫模型(CHMM)以及半连续隐马尔可夫模型(SCHMM)等[3]。
4.4 人工神经元网络(ANN)
人工神经元网络在语音识别中的应用是目前研究的又一热点。ANN实际上是一个超大规模非线性连续时间自适应信息处理系统,它模拟了人类神经元活动的原理,最主要的特征为连续时间非线性动力学、网络的全局作用、大规模并行分布处理及高度的稳健性和学习联想能力。这些能力是HMM模型不具备的。但ANN又不具有HMM模型的动态时间归正性能。因此,人们尝试研究基于HMM和ANN的混合模型,把两者的优点有机结合起来,从而提高整个模型的鲁棒性,这也是目前研究的一个热点。













评论