
人工智能芯片的新用途
来源:semiengineering
 复杂的 AI 流程可以分解为 AI 堆栈 来源:麦肯锡公司对于任何执行复杂算法和计算的 AI 芯片,都有几个关键要求。首先,他们需要能够并行处理数据,使用多个计算元素和宽数据路径来减少延迟。在许多情况下,这还涉及一些与计算元素非常接近的局部内存,以及高带宽内存。其次,这些设备需要针对尺寸、成本和功率预算进行优化,这通常需要根据预计工作负载调整大小的高吞吐量架构。反过来,这需要一些权衡,需要针对特定用例进行平衡。第三,这些架构通常涉及混合处理器来管理复杂的数据流和电源管理方案,其中可能包括 CPU、GPU、FPGA、eFPGA、DSP、NPU、TPU 和 IPU。“在设计中,开发人员需要考虑培训、推理、低功耗、连接性和安全性的要求,”英飞凌物联网、无线和计算业务部首席软件产品营销经理 Danny Watson 说,“种方法可以实现需要本地快速决策的新用例,同时满足当今物联网产品的功耗预算。” Watson 指出,关键是收集正确的数据,以便应用程序可以利用这些数据,从而使他们能够利用技术改进。无处不在的人工智能对于芯片公司来说,这都是一件大事。根据 Precedence Research 的最新报告,整个人工智能市场将从 2021 年的 870 亿美元增长到 2030 年的超过 1.6 万亿美元。这包括数据中心和边缘设备,但增长速度非常快。事实上,人工智能是当今如此热门的领域,几乎所有主要科技公司都在投资或制造人工智能芯片。它们包括苹果、AMD、Arm、百度、谷歌、Graphcore、华为、IBM、英特尔、Meta、NVIDIA、高通、三星和台积电。这个市场五年前几乎不存在,十年前大多数公司都在考虑云计算和高速网关。但是随着带有更多传感器的新设备的推出——无论是汽车、智能手机,甚至是内置某种程度智能的电器,正在生成如此多的数据,因此需要围绕数据的输入、处理、移动和存储设计架构。“在人工智能应用中,正在部署各种技术,”Arteris IP高级技术营销经理 Paul Graykowski 说。“最近的一位客户开发了一种复杂的多通道 ADAS SoC,它可以处理四个传感器数据通道,每个通道都有自己的专用计算和 AI 引擎来处理数据。同样,新的 AI 芯片架构也会不断变化,以满足新应用的需求。”从大到小获得结果的时间通常与芯片间的距离成正比,更短的距离意味着更好的性能和更低的功耗。因此,尽管超大规模数据中心仍需要处理海量数据集,但芯片行业正齐心协力将更多处理转移到下游,无论是机器学习、深度学习还是其他人工智能变体。Cerebras 是深度学习领域的典型代表,在这个领域,速度至关重要,结果的准确性紧随其后。Cerebras 产品管理总监 Natalia Vassilieva 报告说,葛兰素史克公司通过在其表观基因组语言模型中使用晶片级设备,提高了****物发现效率。在一种情况下,葛兰素史克能够将大型化合物库基于深度神经网络的虚拟筛选时间从在GPU集群上运行的183天减少到在大脑设备上运行的3.5天。该“芯片”拥有超过 2.6 万亿个晶体管、85万 个 AI 优化内核、40 GB 片上内存和每秒 20 PB 的内存带宽(1 PB 等于 1,024 TB)。它还消耗 23 kW 的功率,并使用内部闭环、直接对芯片的液体冷却。Graphcore采用了不同的方法,引入了智能处理单元(IPU)技术。通过使用多指令、多数据 (MIMD) 并行性和本地分布式内存,IPU 可以提供 22.4 PFLOPS(每秒 1 petaflop 等于每秒 1000 teraflop),而只需要空气冷却。此外,IPU 在单精度下的理论算术吞吐量高达 31.1 TFLOPS。它比 A100 的 624 TFLOPS 快得多。在 Twitter 进行的一项测试中,IPU 的性能优于 GPU。
复杂的 AI 流程可以分解为 AI 堆栈 来源:麦肯锡公司对于任何执行复杂算法和计算的 AI 芯片,都有几个关键要求。首先,他们需要能够并行处理数据,使用多个计算元素和宽数据路径来减少延迟。在许多情况下,这还涉及一些与计算元素非常接近的局部内存,以及高带宽内存。其次,这些设备需要针对尺寸、成本和功率预算进行优化,这通常需要根据预计工作负载调整大小的高吞吐量架构。反过来,这需要一些权衡,需要针对特定用例进行平衡。第三,这些架构通常涉及混合处理器来管理复杂的数据流和电源管理方案,其中可能包括 CPU、GPU、FPGA、eFPGA、DSP、NPU、TPU 和 IPU。“在设计中,开发人员需要考虑培训、推理、低功耗、连接性和安全性的要求,”英飞凌物联网、无线和计算业务部首席软件产品营销经理 Danny Watson 说,“种方法可以实现需要本地快速决策的新用例,同时满足当今物联网产品的功耗预算。” Watson 指出,关键是收集正确的数据,以便应用程序可以利用这些数据,从而使他们能够利用技术改进。无处不在的人工智能对于芯片公司来说,这都是一件大事。根据 Precedence Research 的最新报告,整个人工智能市场将从 2021 年的 870 亿美元增长到 2030 年的超过 1.6 万亿美元。这包括数据中心和边缘设备,但增长速度非常快。事实上,人工智能是当今如此热门的领域,几乎所有主要科技公司都在投资或制造人工智能芯片。它们包括苹果、AMD、Arm、百度、谷歌、Graphcore、华为、IBM、英特尔、Meta、NVIDIA、高通、三星和台积电。这个市场五年前几乎不存在,十年前大多数公司都在考虑云计算和高速网关。但是随着带有更多传感器的新设备的推出——无论是汽车、智能手机,甚至是内置某种程度智能的电器,正在生成如此多的数据,因此需要围绕数据的输入、处理、移动和存储设计架构。“在人工智能应用中,正在部署各种技术,”Arteris IP高级技术营销经理 Paul Graykowski 说。“最近的一位客户开发了一种复杂的多通道 ADAS SoC,它可以处理四个传感器数据通道,每个通道都有自己的专用计算和 AI 引擎来处理数据。同样,新的 AI 芯片架构也会不断变化,以满足新应用的需求。”从大到小获得结果的时间通常与芯片间的距离成正比,更短的距离意味着更好的性能和更低的功耗。因此,尽管超大规模数据中心仍需要处理海量数据集,但芯片行业正齐心协力将更多处理转移到下游,无论是机器学习、深度学习还是其他人工智能变体。Cerebras 是深度学习领域的典型代表,在这个领域,速度至关重要,结果的准确性紧随其后。Cerebras 产品管理总监 Natalia Vassilieva 报告说,葛兰素史克公司通过在其表观基因组语言模型中使用晶片级设备,提高了****物发现效率。在一种情况下,葛兰素史克能够将大型化合物库基于深度神经网络的虚拟筛选时间从在GPU集群上运行的183天减少到在大脑设备上运行的3.5天。该“芯片”拥有超过 2.6 万亿个晶体管、85万 个 AI 优化内核、40 GB 片上内存和每秒 20 PB 的内存带宽(1 PB 等于 1,024 TB)。它还消耗 23 kW 的功率,并使用内部闭环、直接对芯片的液体冷却。Graphcore采用了不同的方法,引入了智能处理单元(IPU)技术。通过使用多指令、多数据 (MIMD) 并行性和本地分布式内存,IPU 可以提供 22.4 PFLOPS(每秒 1 petaflop 等于每秒 1000 teraflop),而只需要空气冷却。此外,IPU 在单精度下的理论算术吞吐量高达 31.1 TFLOPS。它比 A100 的 624 TFLOPS 快得多。在 Twitter 进行的一项测试中,IPU 的性能优于 GPU。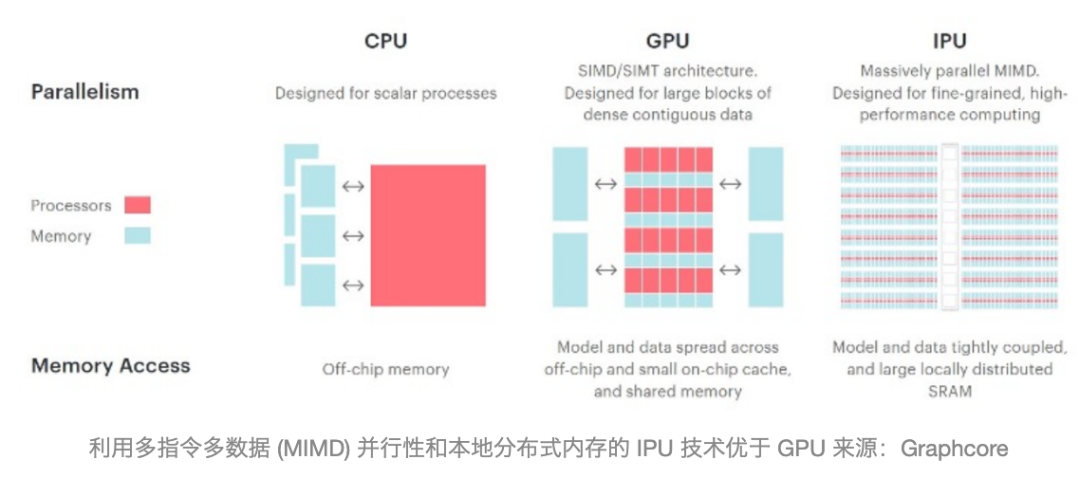 人工智能也可以变小。支持人工智能的智能事物,也称为物联网 (AIoT)/嵌入式人工智能,正在蓬勃发展。根据评估报告,边缘人工智能硬件将从 2020 年的 70 亿美元增长到 2030 年的 390 亿美元。人工智能为边缘计算、网络端点和移动设备增加了智能。随着物联网,越来越多的应用程序正在使用嵌入式人工智能。其中包括可穿戴设备、智能家居和智能遥控器,其中包括一些使用语音识别的设备。同样依赖嵌入式 AI 的还有 AR/VR 游戏、智能汽车面板、物体和运动检测、家庭保健、抄表、智能工厂、智能城市、工业自动化和智能建筑,包括控制和能源管理。Cadence Tensilica AI 产品的产品营销总监 Suhas Mitra 表示:“AI 能够在本地更快地处理数据,从而使物联网计算更加高效。这包括提供更好的响应时间和更小的延迟,因为生成的数据也在边缘设备上即时处理。执行人工智能边缘处理将更加可靠,因为它可能并不总是能够通过实时无线或有线连接不断向云发送大量数据。它还减轻了存储和处理大量数据的压力云中的大量数据,可能包含个人和敏感信息。关于向云发送用户信息的隐私问题可能会导致不经同意就无法上传数据。做更多的边缘计算可以延长电池寿命,因为当使用人工智能方法时,一些计算在边缘平台上需要更少的周期。因此,消耗的能量更少,散热也更低。”在进行推理之前,所有的 AI 芯片都需要经过训练。虽然数据集通常非常大,需要大型数据中心进行培训,但可以在个人计算机或开发系统级别进行进一步培训。开发人员将经历一个艰苦的过程,以确保实现最佳推理算法。许多 AI 芯片制造商为其客户提供培训合作伙伴名单。即使有顾问的帮助,开发人员仍然需要支付咨询时间并完成培训工作。一种更简单的方法是使用预训练模型来实现,例如 Flex Logix 的 EasyVision 平台。通过预先培训的X1M模块芯片,开发人员可以绕过培训过程,直接进行产品开发和测试。” Flex Logix推理营销高级总监 Sam Fuller 说。“经过预训练的解决方案已经过现场测试和验证,比开发人员的试错法效率更高。通常,专用预训练芯片比常规CPU效率更高。”想得更小将 AI 包含在更小的设备中的可能性也在增加,这要归功于由 tinyML 基金会建立的微型机器学习,以支持在 mW 范围内运行的嵌入式设备机器学习和数据分析。其中许多设备可以在视觉、音频、惯性测量单元(IMU)和生物医学中执行ML。此外,它还提供了一个名为 ScaleDown 的开源神经网络优化框架,以简化将 ML 模型部署到 tinyML 设备的过程。TinyML 可以在任何可编程 AI 芯片上运行,包括 Arduino 板。Arduino 的使命是为爱好者、学生和教育工作者提供电子设备和软件。它经过多年的发展,基于 Arduino 的解决方案已用于当今的许多工业领域。但是结合 tinyML 和 Arduino 硬件可能会提供非常低成本的嵌入式 AI 解决方案,典型的硬件成本不到 100 美元。在这些微型设备中设计人工智能的挑战之一是功率预算。Synaptics 已经接受了开发低功耗预算 AI 和传感器芯片的挑战。据领导 Synaptics 低功耗 AI 产品线的高级产品经理 Ananda Roy 表示该公司的Katana AI SoC能够进行人员检测/计数和跌倒检测,并可以在24 MHz下以30 mW或90 MHz的更高功率运行主动AI视觉推断。深度睡眠模式的功耗小于100µW。总的来说,它比其他AI芯片更节能。为了实现高效的电源管理,神经处理单元 (NPU) 依赖于具有多个存储体的存储架构,这些存储体可以在不使用时设置为超低功耗模式,以及可扩展的工作电压和处理器速度,就像踩在当你需要你的车开得更快时加油。FlexSense 是一款用于 AI 应用的传感器芯片,其设计结合了低功耗 RISC CPU 和模拟硬件前端,该前端经过高度优化,可有效转换电感和电容传感器输入。与车载霍尔效应和温度传感器一起,它包括四个传感器,用于检测触摸、力、接近度和温度等输入,所有这些都在一个小封装中(1.62 x 1.62 mm),在睡眠模式下仅使用240µW或10µW。
人工智能也可以变小。支持人工智能的智能事物,也称为物联网 (AIoT)/嵌入式人工智能,正在蓬勃发展。根据评估报告,边缘人工智能硬件将从 2020 年的 70 亿美元增长到 2030 年的 390 亿美元。人工智能为边缘计算、网络端点和移动设备增加了智能。随着物联网,越来越多的应用程序正在使用嵌入式人工智能。其中包括可穿戴设备、智能家居和智能遥控器,其中包括一些使用语音识别的设备。同样依赖嵌入式 AI 的还有 AR/VR 游戏、智能汽车面板、物体和运动检测、家庭保健、抄表、智能工厂、智能城市、工业自动化和智能建筑,包括控制和能源管理。Cadence Tensilica AI 产品的产品营销总监 Suhas Mitra 表示:“AI 能够在本地更快地处理数据,从而使物联网计算更加高效。这包括提供更好的响应时间和更小的延迟,因为生成的数据也在边缘设备上即时处理。执行人工智能边缘处理将更加可靠,因为它可能并不总是能够通过实时无线或有线连接不断向云发送大量数据。它还减轻了存储和处理大量数据的压力云中的大量数据,可能包含个人和敏感信息。关于向云发送用户信息的隐私问题可能会导致不经同意就无法上传数据。做更多的边缘计算可以延长电池寿命,因为当使用人工智能方法时,一些计算在边缘平台上需要更少的周期。因此,消耗的能量更少,散热也更低。”在进行推理之前,所有的 AI 芯片都需要经过训练。虽然数据集通常非常大,需要大型数据中心进行培训,但可以在个人计算机或开发系统级别进行进一步培训。开发人员将经历一个艰苦的过程,以确保实现最佳推理算法。许多 AI 芯片制造商为其客户提供培训合作伙伴名单。即使有顾问的帮助,开发人员仍然需要支付咨询时间并完成培训工作。一种更简单的方法是使用预训练模型来实现,例如 Flex Logix 的 EasyVision 平台。通过预先培训的X1M模块芯片,开发人员可以绕过培训过程,直接进行产品开发和测试。” Flex Logix推理营销高级总监 Sam Fuller 说。“经过预训练的解决方案已经过现场测试和验证,比开发人员的试错法效率更高。通常,专用预训练芯片比常规CPU效率更高。”想得更小将 AI 包含在更小的设备中的可能性也在增加,这要归功于由 tinyML 基金会建立的微型机器学习,以支持在 mW 范围内运行的嵌入式设备机器学习和数据分析。其中许多设备可以在视觉、音频、惯性测量单元(IMU)和生物医学中执行ML。此外,它还提供了一个名为 ScaleDown 的开源神经网络优化框架,以简化将 ML 模型部署到 tinyML 设备的过程。TinyML 可以在任何可编程 AI 芯片上运行,包括 Arduino 板。Arduino 的使命是为爱好者、学生和教育工作者提供电子设备和软件。它经过多年的发展,基于 Arduino 的解决方案已用于当今的许多工业领域。但是结合 tinyML 和 Arduino 硬件可能会提供非常低成本的嵌入式 AI 解决方案,典型的硬件成本不到 100 美元。在这些微型设备中设计人工智能的挑战之一是功率预算。Synaptics 已经接受了开发低功耗预算 AI 和传感器芯片的挑战。据领导 Synaptics 低功耗 AI 产品线的高级产品经理 Ananda Roy 表示该公司的Katana AI SoC能够进行人员检测/计数和跌倒检测,并可以在24 MHz下以30 mW或90 MHz的更高功率运行主动AI视觉推断。深度睡眠模式的功耗小于100µW。总的来说,它比其他AI芯片更节能。为了实现高效的电源管理,神经处理单元 (NPU) 依赖于具有多个存储体的存储架构,这些存储体可以在不使用时设置为超低功耗模式,以及可扩展的工作电压和处理器速度,就像踩在当你需要你的车开得更快时加油。FlexSense 是一款用于 AI 应用的传感器芯片,其设计结合了低功耗 RISC CPU 和模拟硬件前端,该前端经过高度优化,可有效转换电感和电容传感器输入。与车载霍尔效应和温度传感器一起,它包括四个传感器,用于检测触摸、力、接近度和温度等输入,所有这些都在一个小封装中(1.62 x 1.62 mm),在睡眠模式下仅使用240µW或10µW。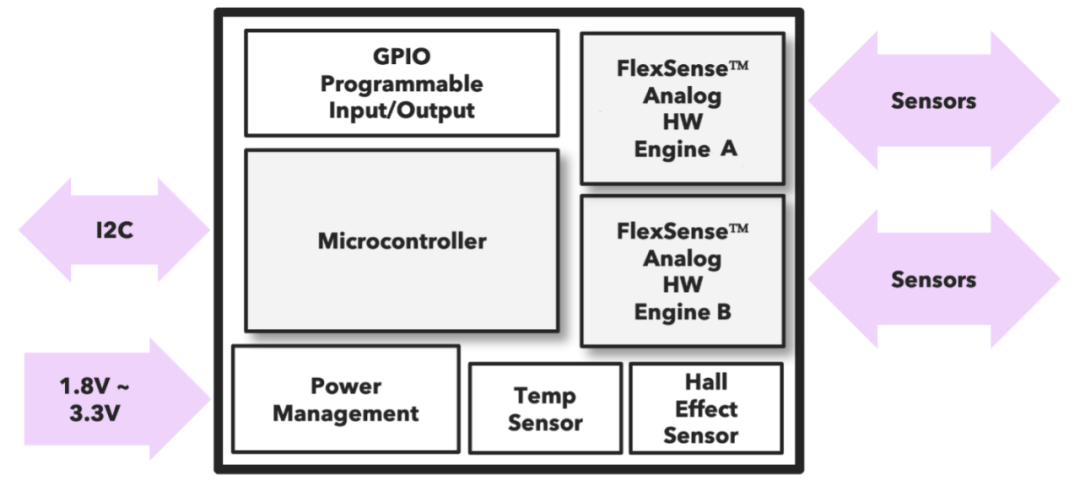 低功耗传感器采用小封装 (1.62 x 1.62 mm) 来源:Synaptics安全问题和改进在安全方面,人工智能既是一个潜在的漏洞,也是一个潜在的解决方案。随着人工智能芯片针对特定用例进行了优化,算法也在不断更新,业界的经验教训会减少,攻击面也会扩大。但人工智能也可用于识别数据流量中的异常模式,发出警报或自动关闭受影响的电路,直到可以进行更多分析。恩智浦产品经理 Srikanth Jagannathan 指出了电池驱动设备的功能、芯片安全性和低功耗的正确组合的重要性。i.MX AI芯片结合了Arm的低功耗Cortex-M33、Arm TrustZone和NXP的片上EdgeLock、嵌入式ML和多i/O。功耗约为2.5瓦。然而,它能够提供1个TOPS的性能(在 1 GHz 下进行 512 次并行乘法累加运算)。
低功耗传感器采用小封装 (1.62 x 1.62 mm) 来源:Synaptics安全问题和改进在安全方面,人工智能既是一个潜在的漏洞,也是一个潜在的解决方案。随着人工智能芯片针对特定用例进行了优化,算法也在不断更新,业界的经验教训会减少,攻击面也会扩大。但人工智能也可用于识别数据流量中的异常模式,发出警报或自动关闭受影响的电路,直到可以进行更多分析。恩智浦产品经理 Srikanth Jagannathan 指出了电池驱动设备的功能、芯片安全性和低功耗的正确组合的重要性。i.MX AI芯片结合了Arm的低功耗Cortex-M33、Arm TrustZone和NXP的片上EdgeLock、嵌入式ML和多i/O。功耗约为2.5瓦。然而,它能够提供1个TOPS的性能(在 1 GHz 下进行 512 次并行乘法累加运算)。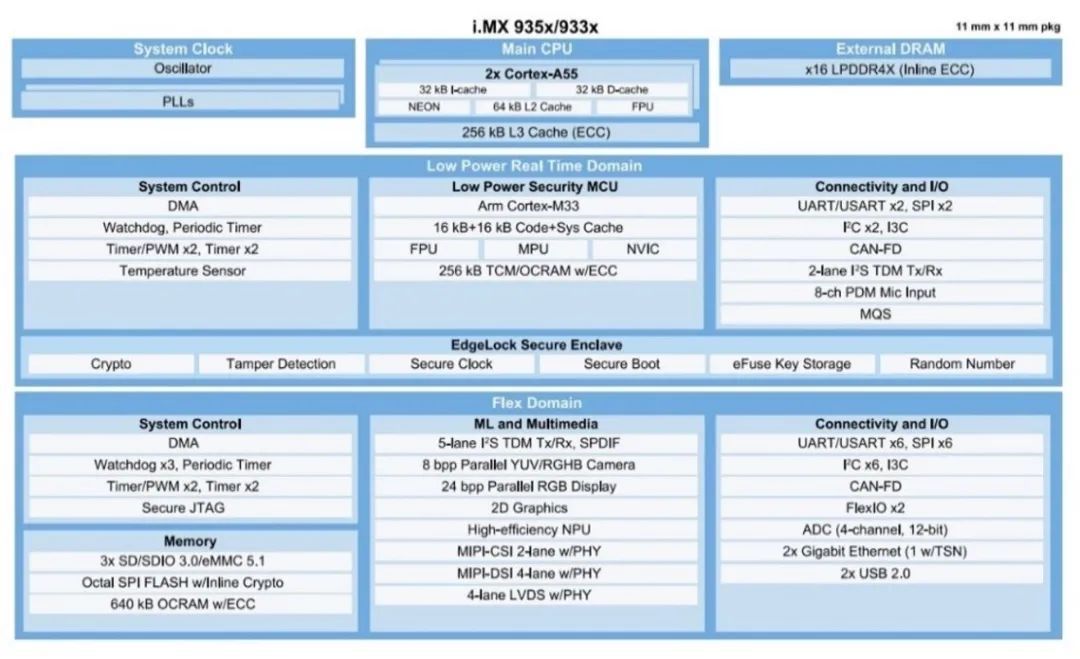 i.MX AI 芯片将 Arm 的低功耗 Cortex-M33 与 Arm TrustZone 和NXP 的片上 EdgeLock、嵌入式 ML 和多个 I/O 相结合 来源:恩智浦西门子 EDA 嵌入式软件部门的高级产品经理 Kathy Tufto指出需要建立软件信任链,但这从硬件开始。目标是防止任何未经过身份验证和验证的代码执行。在她确定的解决方案中:
i.MX AI 芯片将 Arm 的低功耗 Cortex-M33 与 Arm TrustZone 和NXP 的片上 EdgeLock、嵌入式 ML 和多个 I/O 相结合 来源:恩智浦西门子 EDA 嵌入式软件部门的高级产品经理 Kathy Tufto指出需要建立软件信任链,但这从硬件开始。目标是防止任何未经过身份验证和验证的代码执行。在她确定的解决方案中:
- 静态数据:安全的信任引导根和信任访问控制的软件链。
- Data at Motion:安全协议和加密加速。
- 使用中的数据:通过内存管理单元 (MMU) 进行硬件强制分离。

*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。










