
千亿参数的大模型,需要多少算力?
备注:现场视频请查阅「CSDN视频号」

「百模争秀」时代的算力瓶颈
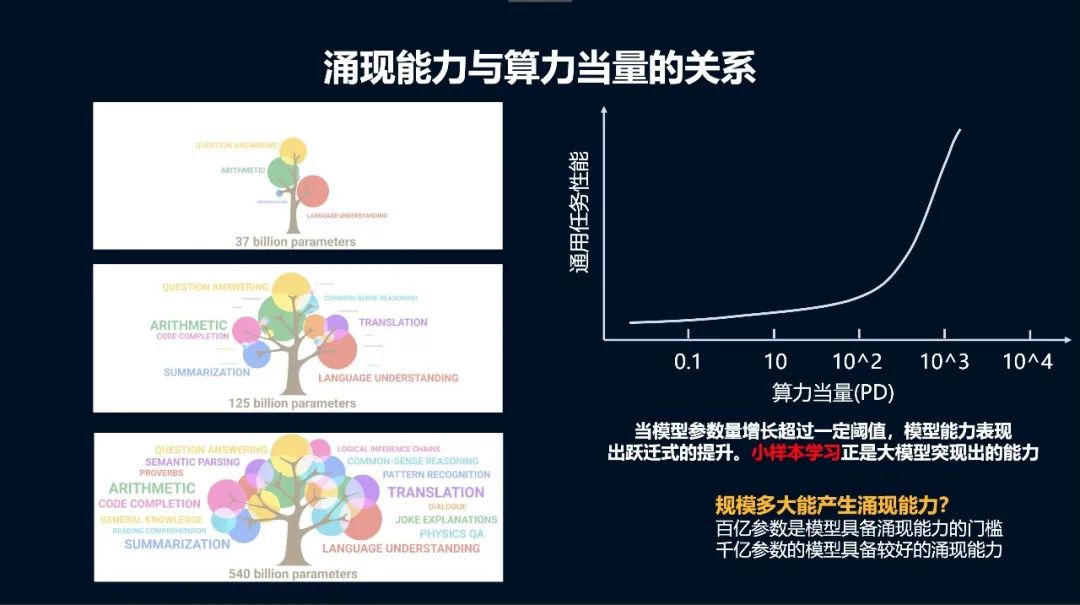 现在来看,百亿参数是模型具备涌现能力的门槛,千亿参数的模型具备较好的涌现能力。但这并不意味着模型规模就要上升到万亿规模级别的竞争,因为现有大模型并没有得到充分训练,如 GPT-3 的每个参数基本上只训练了 1-2 个Token,DeepMind 的研究表明,如果把一个大模型训练充分,需要把每个参数量训练 20 个 Token。所以,当前的很多千亿规模的大模型还需要用多 10 倍的数据进行训练,模型性能才能达到比较好的水平。
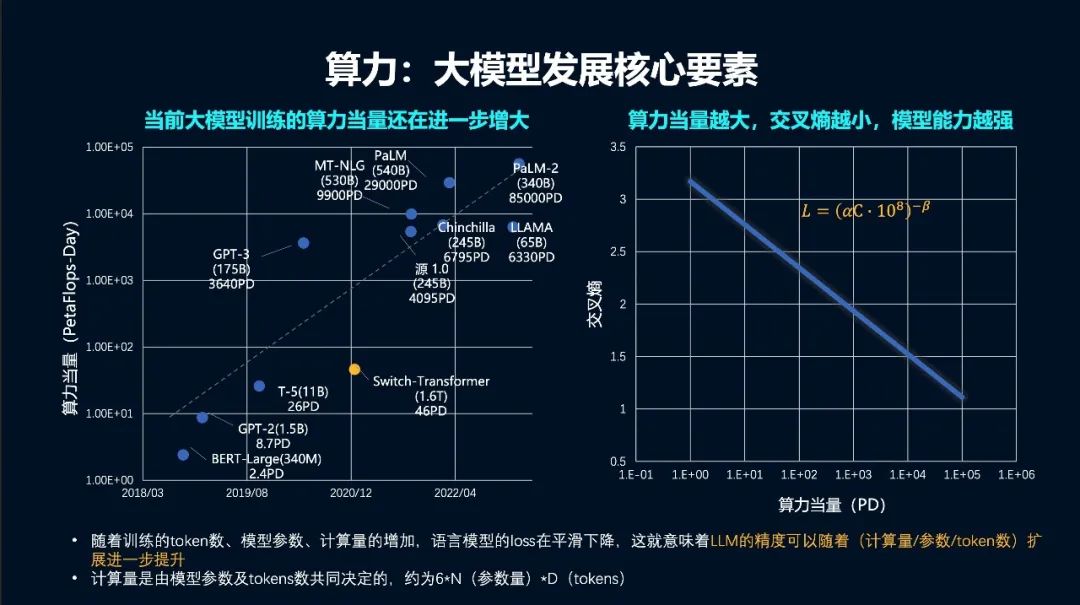
现在来看,百亿参数是模型具备涌现能力的门槛,千亿参数的模型具备较好的涌现能力。但这并不意味着模型规模就要上升到万亿规模级别的竞争,因为现有大模型并没有得到充分训练,如 GPT-3 的每个参数基本上只训练了 1-2 个Token,DeepMind 的研究表明,如果把一个大模型训练充分,需要把每个参数量训练 20 个 Token。所以,当前的很多千亿规模的大模型还需要用多 10 倍的数据进行训练,模型性能才能达到比较好的水平。无论是提高模型参数量还是提升数据规模,算力依旧是大模型能力提升的核心驱动力:需要用「足够大」的算力,去支撑起「足够精准」模型泛化能力。当前大模型训练的算力当量还在进一步增大,从 GPT-3 到 GPT-4 算力当量增长了 68 倍。算力当量越大,交叉熵越小,模型能力越强。随着训练的 token 数、模型参数、计算量的增加,语言模型的 loss 在平滑下降,这就意味着大语言模型的精度可以随着计算量、参数规模、token 数扩展进一步提升。

大模型能力来源于大量工程实践经验,预训练的工程挑战巨大,这表现在如下几个方面:首先,AI 大模型的演化对于集群的并行运算效率、片上存储、带宽、低延时的访存等也都提出了较高的需求,万卡AI平台的规划建设、性能调优、算力调度都是很难解决的难题;其次,大规模训练普遍存在硬件故障、梯度爆炸等小规模训练不会遇到的问题;再次,工程实践方面的缺乏导致企业难以在模型质量上实现快速提升。作为最早布局大模型的企业之一,浪潮信息在业界率先推出了中文 AI 巨量模型「源 1.0」,参数规模高达 2457 亿。千亿参数规模的大模型创新实践,使得浪潮信息在大模型领域积累了实战技术经验并拥有专业的研发团队,为业界提供AI算力系统参考设计。在算力效率层面,针对大模型训练中存在计算模式复杂,算力集群性能较低的情况。源 1.0 在大规模分布式训练中采用了张量并行、流水线并行和数据并行的三维并行策略,使用 266 台 8 卡 NVLINK A100 服务器,训练耗时约 15 天,单卡计算效率约 44%。共计训练了 180 billion token,并将模型最后的 loss 值收敛至 1.73,显著低于 GPT-3 等业界其他语言模型。
 首次提出面向效率和精度优化的大模型结构协同设计方法,围绕深度学习框架、训练集群 IO、通信开展了深入优化,在仅采用 2x200G 互联的情况下,源 1.0的算力效率达到 45%,算力效率世界领先。在集群高速互联层面,基于原生 RDMA 实现整个集群的全线速组网,并对网络拓扑进行优化,可以有效消除混合计算的计算瓶颈,确保集群在大模型训练时始终处于最佳状态。
首次提出面向效率和精度优化的大模型结构协同设计方法,围绕深度学习框架、训练集群 IO、通信开展了深入优化,在仅采用 2x200G 互联的情况下,源 1.0的算力效率达到 45%,算力效率世界领先。在集群高速互联层面,基于原生 RDMA 实现整个集群的全线速组网,并对网络拓扑进行优化,可以有效消除混合计算的计算瓶颈,确保集群在大模型训练时始终处于最佳状态。
当前,中国和业界先进水平大模型的算力差距依然较大,从算力当量来看,GPT-4 的算力当量已经达到了 248,842PD,而国内大多数主流的大模型算力大量仅为数千 PD,差距高达近百倍。同时,中国和业界先进水平大模型在算法、数据方面也存在巨大差距。在算法方面,虽然开源为国内大模型发展带来了弯道超车的良机,但 LLaMA 等开源大模型相比 GPT4 等顶级水平自研模型的性能,开源模型的能力存在「天花板」。
 在数据方面,中文数据集和英文数据集相比较,在规模、质量上均存在显著差距,相较于动辄数千亿单词量级的英文数据,中文大模型的数据量级仅为百亿左右,而且开源程度较低,封闭程度较高。开发大模型、发展通用人工智能是一项非常复杂的系统工程,我们亟需从系统层面为未来大模型的良好生态发展寻找最优解。从实战中走来,通过构建高效稳定的智算系统,加速模型开发效率提升。
在数据方面,中文数据集和英文数据集相比较,在规模、质量上均存在显著差距,相较于动辄数千亿单词量级的英文数据,中文大模型的数据量级仅为百亿左右,而且开源程度较低,封闭程度较高。开发大模型、发展通用人工智能是一项非常复杂的系统工程,我们亟需从系统层面为未来大模型的良好生态发展寻找最优解。从实战中走来,通过构建高效稳定的智算系统,加速模型开发效率提升。*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。







