
视频图像中文本的检测、定位与提取
目前,基于内容的视频信息检索(Content―Based Video Retrieval,简称CBVR)的研究已取得了较大的进展,但是检索所采用的特征基本上都是低级视觉特征,如颜色、纹理、形状、空间关系和运动等。这其中存在的主要问题是低级视觉特征对视频的描述与人对视频的描述存在较大差异,而且用户也不熟悉特征值的变化对视觉效果带来的影响。而视频本质上是由文本、视频和音频等多种媒质融合而成,它们之间存在语义关联,一种媒质和另外一种媒质表示同一语义或是其补充。只有通过挖掘构成视频的各种媒质所表达的丰富语义信息,克服单纯的视觉特征语义表达能力较弱这一缺点,充分提取视频中的高层语义,才能符合人们对视频信息的理解习惯,实现实用的基于内容的视频检索系统。
本文引用地址://m.amcfsurvey.com/article/103942.htm在视频中,文本信息(如新闻标题、节目内容、旁白、工作人员名单等)均包含了丰富的高层语义信息,可用于对相应视频流所表达的事件、情节以及情感等进行高级语义标注。如果这些文本能自动地被检测、分割、识别出来,则对视频高层语义的自动理解、索引和检索是非常有价值的。视频中的文本分为人工文本和场景文本。目前的研究主要集中于人工文本,而场景文本的研究才刚刚起步。正是由于文本的种类、形状的多样差异性,目前文本提取算法还没有一个通用的评价准则和标准数据库。
文中针对水平和竖直排列的静止及滚动文本,提出利用小波多尺度局部模极大值边缘检测算法来检测文本图像边缘,利用形态学处理生成候选文本区域,用由粗到精的多次水平、竖直投影来定位精确的文本位置。然后,对于文本子图用局部Otsu方法和区域填充处理进行文字二值化提取。
1 小波模极大值算法提取视频图像的文字边缘
1.1 二维小波变换模极大值原理
设θ(x,y)是一个二维平滑函数,引入尺度因

模M2jf(x,y)取极大值的点(x,y)对应于f*θs(x,y)的突变点或尖锐陡峭变化的位置,从而对应于图像f(x,y)的边缘。梯度grad(f*θs)(x,y)在点(x,y)处的方向表示在图像平面(x,y)上f(x,y)的方向导数的绝对值取极大值的方向。即计算一个光滑函数的导数沿梯度方向的模极大值等价于计算其小波变换的模极大值。
1.2 文本图像的边缘提取
在图像中,文本字符具有特殊的线条结构和纹理特点,其灰度(颜色)与背景相差较大,边缘变化剧烈,呈现出明显的横向、竖向、斜向边缘特征,中、高频信息较强。在小波图像中表现为相应区域高频细节子图的系数较大;横向线条、竖向线条和斜向线条分别在LH,HL以及HH子图相应位置表现为较大的小波系数。

根据上述原理,在实际计算时,采用3次B样条小波,对输入灰度文中图像进行保持图像大小不变的二维小波变换,得到W12jf(x,y)和W22jf(x,y)。改变j的值得到在不同尺度下图像的小波变换,文中选取小波分解最大尺度为J=3,其中1≤J≤J。由式(2)、式(3)计算每一点的模值和幅角,找出模图像在梯度方向上的极大值。设置阈值T0,保留大于T的像素的模值。最后连接边界点,形成边缘。
图1(a)为使用小波模极大值算法提取的视频图像中的文字边缘,图1(b)、(c)、(d)分别为使用Canny算子、LOG算子和Sobel算子的结果。由图1可知,文中方法比传统边缘检测方法,能在检测出文本边缘的同时很好的抑制背景边缘。
2 文本定位
由于有的图像背景过于复杂,在上阶段处理得到的边缘图中仍存在一定数量的背景边缘噪声,将其通过局部阈值处理来滤除;在采用形态学处理生成候选文本区域后,用基于局部区域直方图和阈值的定位方法对水平和竖直文本进行定位;为适应不同尺度文本,采用两层金字塔模型分别定位并合成结果。
2.1 背景噪声滤除
受文献的启发,用两个同心窗对当前待处理的二值边缘图像EMP进行扫描。在实验中,选择经验值,外窗高为3h=30,内窗高为h=10,以h为步长进行扫描。根据外窗中的边缘密度直方图来决定对内窗处理时的阈值。同心窗的结构及外窗内的边缘水平投影,如图2所示,Pi(i=1,…,3h)是第i行的边缘像素数目。内窗内的局部阈值Tkernel就可以按照下面的公式计算

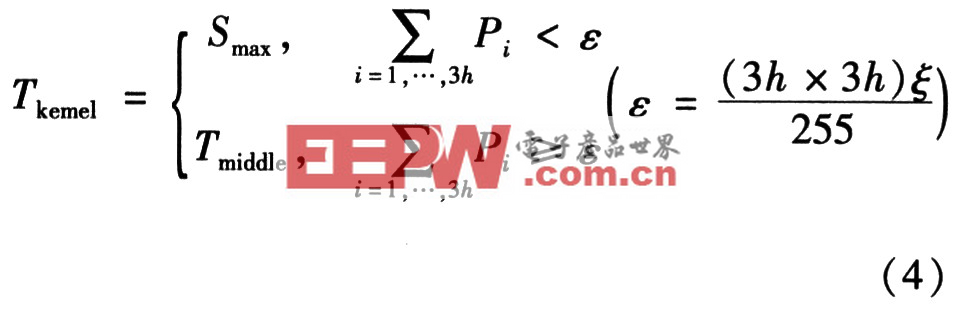
其中,Smax是最高边缘强度(O或255)。由式(4)可见,如果外窗内的边缘像素的数量非常少,密度小于某个阈值ξ,那么内窗内就很可能是背景噪声,则将内窗内的阈值设置为Smax;否则,内窗内很可能是一个文本区域,将内窗内的阈值设置为Tmiddle,Tmiddle可以是0~255中任意一个数字。则在当前扫描窗口,内窗内大于阈值的边缘像素被标记为文本;否则,将其值设置为0,即小于阈值的边缘像素被覆盖掉。
2.2 基于形态学的候选文本区域生成
形态学可将图像信号与其几何形状联系起来,用具有一定形态的结构元素去量度和提取图像中的对应形状以达到对图像分析和识别的目的。所以文中采用形态学处理来形成候选文本区域。形态学最基本的概念是腐蚀和膨胀,以及由它们组合而成的各种形态操作算子。
设Ω为二维欧几里德空间,图像A是Ω的一个子集,结构元素B也是Ω的一个子集,b∈Ω是欧氏空间的一个点,定义4个基本运算:

其中,膨胀具有扩大目标区域的作用,腐蚀具有收缩目标区域的作用,开运算可删除目标区域中的小分支,闭运算可填补目标区域中的空洞。 基于以上4个运算,文中的形态处理流程为:选取3×3的矩型结构元素进行膨胀,然后用2×2的矩型结构元素进行腐蚀,再用长为7,角度为0°的线型结构元素进行闭运算处理。考虑到竖直文本的情况,再用长为4,角度为90°的线型结构元素进行闭运算处理。实验发现,结构元素的尺寸太大,会导致无效的膨胀重叠现象,增大计算量;而结构元素尺寸过小将不能有效形成文本块区域。所以结构元素B的选择对于候选文本区域形成与文本区域提取至关重要。实验证明,文中所采用的结构元素很好地形成了候选文本区域。
2.3 基于两层金字塔和局部区域直方图的文本定位
对于生成候选文本区域的边缘图,在原图和分辨率降低一半的图像这两个尺度的金字塔级别上分别采用由粗到精的多次水平、竖直投影,并合成结果,来确定文本块的具体行列。对水平文本定位先水平投影后竖直投影,对竖直文本定位则交换投影顺序。
定义一种局部区域的直方图(Local Region histogram,即LRH)如下:
给定一幅图像f(x,y),对于其中由若干连续的行或列(行数或列数为L)所构成的任意子图像,可分别按行或列生成局部区域直方图LRH。LRH函数可定义为
其中,k为子图像的像素行(列)号,N表示一行(列)中的像素总数,Nk则是经过处理的边缘图中的高亮像素数,即是代表文本所在位置的那些白色像素数。图3给出了一幅处理后的边缘图像所生成的LRH图。
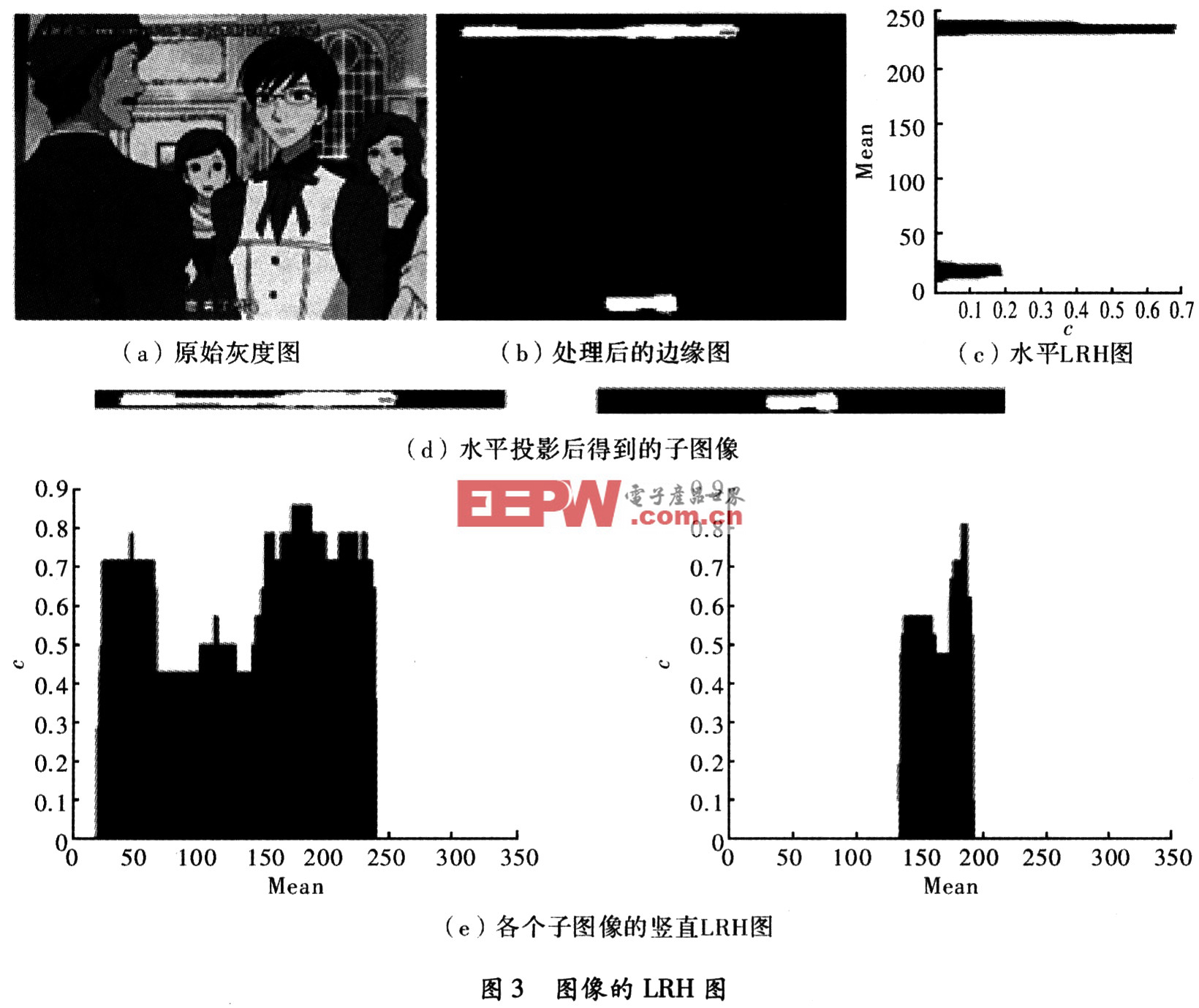
由图3可见,文本区域在LRH图中形成具有一定宽度的高函数值连续区域。利用阈值法来检测行/列边界,由于阈值T取值过小会造成不能分割出单独的行/列,过大则会遗漏行/列。为了能自动适应不同的图像,将阈值T定义为T=c*Mean(LRH)。c为一个微调系数,可根据不同的视频源的统计特性进行调整。针对文中选取的视频片段,在进行了大量实验对比后,选取了实验效果较好的经验值,对于水平的LRH图,选择c为1.O;对于竖直的LRH图,选择c为0.5。
最后,对标出的矩形框,根据文本的尺寸比例,制定简单的约束条件来去除非文本区。
3 文本二值化提取
为适应OCR软件识别,需将文本子图转换成二值化图像。在进行二值化前,采用双三次插值法将所有水平文本区域高度归一化成60像素,而宽度则根据原区域的比例进行相应的放大或缩小(对于竖直排列的文字块则放缩到60像素宽,高度随比例放缩)。为了增强文本子图中字符与背景的对比度,对插值后的图像进行灰度拉伸,自动搜索直方图上非0最小值a和最大值b,把[a,b]拉伸到[0,255]的整个区间。采用文献中的方法对文字极性进行判断,并将其统一为“白底黑字”的形式。
Otsu算法是一种最大类间方差法,能够自动选取阈值,来分割图像成两部分。对于以上处理得到的图像,二值化过程采用文献中的基于滑动窗口的局部自适应Otsu方法和向内填充的区域生长方法,并对区域生长方法的文本标记做了改进。根据文本字符的笔划特点,对文本点定义水平、竖直、右对角和左对角4个方向连通长度,对文本进行标记保护。将文本像素标记点定义为

MIN_W,MAX_W和MAX_L定义了连通最长数目的范围。经过此步骤,再对背景进行填充,并将连通区域面积过小的噪声点去除。最后送入汉王OCR5.0增强版软件进行识别。图4给出了二值化过程。

4 实验及分析
为了验证文中检测定位算法的性能,人工挑选了150帧背景非常复杂的视频图像进行了测试。其中有中文也有英文,有静止也有线性滚动,有单行也有多行文本,字体多样,尺寸有大有小。在实验之前已经手工统计了这150帧图像中所包含的文本块总数,实验结果,如表l所示。

其中,误检的原因主要是复杂背景下存在与文本相似性很高的区域,而漏检的原因是由于该文本区域与周围背景对比度太低,几乎完全溶入到背景中或单独出现的字符在一系列处理中不满足文本块的尺寸限定而被当作背景噪声滤除掉。采用软件汉王OCR5.0增强版对二值化后的文本字符的最终识别率为88.7%。
5 结束语
提出采用小波多尺度局部模极大值边缘检测方法来对文本图像进行边缘检测。对于检测到的文本边缘图,先用局部阈值处理来滤除背景噪声,采用形态学处理生成候选文本区域。使用由粗到精的递归投影和基于局部区域直方图的定位算法,利用两层金字塔模型以检测出大小不一的文本来降低漏检率,并用相应的准则来消除虚假的文本区域。文本提取方面,采用双三次插值来统一各文本的高度/宽度,用灰度拉伸的方法来增强文本图像的分辨率。然后用改进的Otsu方法和种子填充方法进行二值化,去除连通面积过小的噪声点,最后送入OCR软件进行识别。实验结果证明本文算法对于提取视频图像文本的有效性。
绝对值编码器相关文章:绝对值编码器原理
全息投影相关文章:全息投影原理





评论