
国内AI芯片百家争鸣,何以抗衡全球技术寡头
计算机视觉领域的搅局者——英特尔
本文引用地址://m.amcfsurvey.com/article/201804/377915.htm英特尔作为世界上最大的计算机芯片制造商,近年来一直在寻求计算机以外的市场,其中人工智能芯片争夺成为英特尔的核心战略之一。为了加强在人工智能芯片领域的实力,不仅以 167 亿美元收购 FPGA 生产商 Altera 公司,还以 153 亿美元收购自动驾驶技术公司 Mobileye,以及机器视觉公司 Movidius 和为自动驾驶汽车芯片提供安全工具的公司 Yogitech,背后凸显这家在 PC 时代处于核心位置的巨头面向未来的积极转型。

Myriad X就是英特尔子公司 Movidius 在 2017 年推出的视觉处理器 (VPU,vision processing unit),这是一款低功耗的系统芯片 (SoC),用于在基于视觉的设备上加速深度学习和人工智能——如无人机、智能相机和 VR / AR 头盔。Myriad X 是全球第一个配备专用神经网络计算引擎的片上系统芯片(SoC),用于加速设备端的深度学习推理计算。该神经网络计算引擎是芯片上集成的硬件模块,专为高速、低功耗且不牺牲精确度地运行基于深度学习的神经网络而设计,让设备能够实时地看到、理解和响应周围环境。引入该神经计算引擎之后,Myriad X 架构能够为基于深度学习的神经网络推理提供 1TOPS 的计算性能。
执 “能效比” 之牛耳——学术界
除了工业界和厂商在人工智能领域不断推出新产品之外,学术界也在持续推进人工智能芯片新技术的发展。
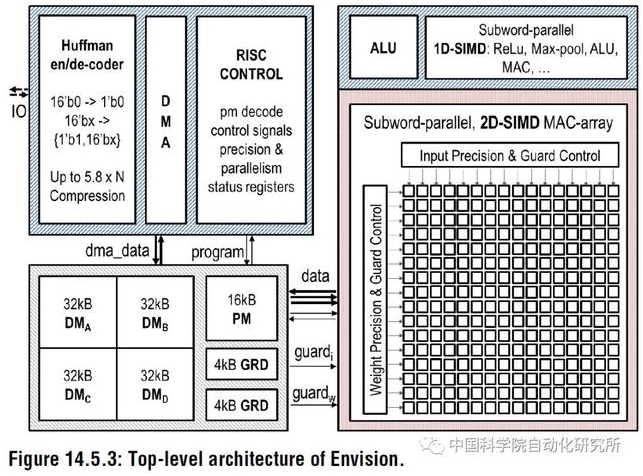
比利时鲁汶大学的 Bert Moons 等在 2017 年顶级会议 IEEE ISSCC 上面提出了能效比高达 10.0TOPs/W 的针对卷积神经网络加速的芯片 ENVISION,该芯片采用 28nm FD-SOI 技术。该芯片包括一个 16 位的 RISC 处理器核,1D-SIMD 处理单元进行 ReLU 和 Pooling 操作,2D-SIMD MAC 阵列处理卷积层和全连接层的操作,还有 128KB 的片上存储器。
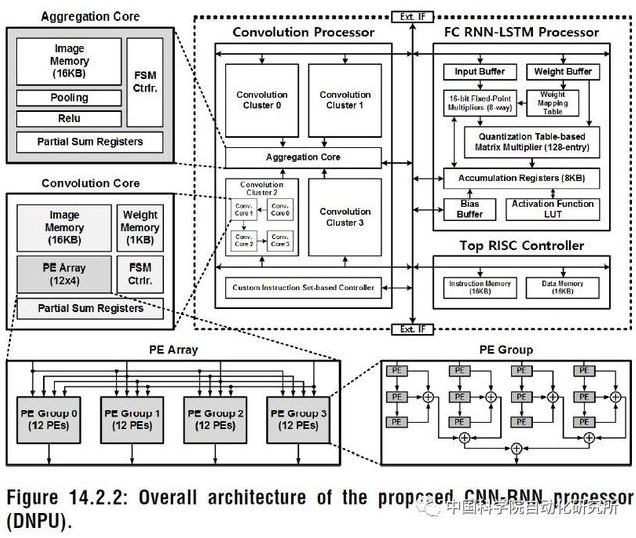
韩国科学技术院 KAIST 的 Dongjoo Shin 等人在 ISSCC2017 上提出了一个针对 CNN 和 RNN 结构可配置的加速器单元 DNPU,除了包含一个 RISC 核之外,还包括了一个针对卷积层操作的计算阵列 CP 和一个针对全连接层 RNN-LSTM 操作的计算阵列 FRP,相比于鲁汶大学的 Envision,DNPU 支持 CNN 和 RNN 结构,能效比高达 8.1TOPS/W。该芯片采用了 65nm CMOS 工艺。
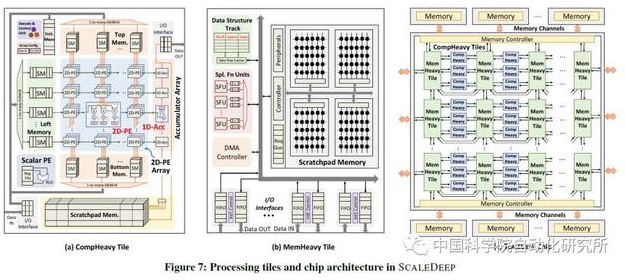
相比较于鲁汶大学和韩国科学技术院都针对神经网络推理部分的计算操作来说,普渡大学的Venkataramani S 等人在计算机体系结构顶级会议 ISCA2017 上提出了针对大规模神经网络训练的人工智能处理器 SCALLDEEP。
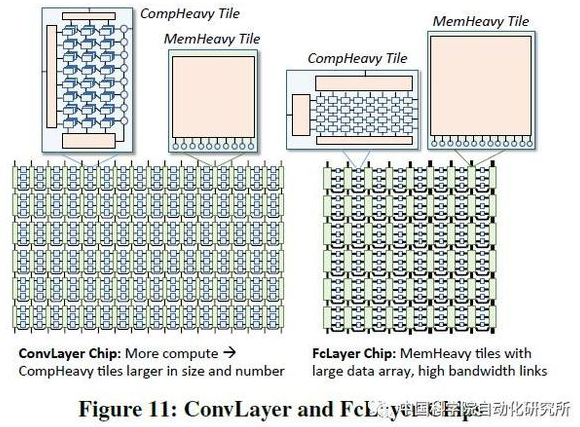
该论文针对深度神经网络的训练部分进行针对性优化,提出了一个可扩展服务器架构,且深入分析了深度神经网络中卷积层,采样层,全连接层等在计算密集度和访存密集度方面的不同,设计了两种处理器 core 架构,计算密集型的任务放在了 comHeavy 核中,包含大量的 2D 乘法器和累加器部件,而对于访存密集型任务则放在了 memHeavy 核中,包含大量 SPM 存储器和 tracker 同步单元,既可以作为存储单元使用,又可以进行计算操作,包括 ReLU,tanh 等。而一个 SCALEDEEP Chip 则可以有不同配置下的两类处理器核组成,然后再组成计算簇。
论文中所用的处理平台包括 7032 个处理器 tile。论文作者针对深度神经网络设计了编译器,完成网络映射和代码生成,同时设计了设计空间探索的模拟器平台,可以进行性能和功耗的评估,性能则得益于时钟精确级的模拟器,功耗评估则从 DC 中提取模块的网表级的参数模型。该芯片仅采用了 Intel 14nm 工艺进行了综合和性能评估,峰值能效比高达 485.7GOPS/W。








评论