
基于GPU的并行Voronoi图栅格生成算法

具体步骤如下:(这里假设栅格的规模为M×N):
Step1:根据栅格图像的规模,确定GPU端线程块和线程的分配方式和分配数量,初始化GPU端的参数。
Step2:程序调用GPU端内核函数,同时将待处理栅格图像数据传入GPU中。数据主要是图像的栅格距离,一般是二维数组,0表示空白栅格,其他各生长目标可由1,2等不同的数字定义。
Step3:GPU分配M×N个thread对栅格进行处理,当M×N大于所有的thread的总数时,可以将M×N个栅格分块处理,即将其分成A行×B列×C块,其中A×B小于thread的总数。对于分成了C块的栅格来说,每个线程只需要处理C个栅格。
Step4:当生长目标数目不多时,每一个线程计算其对应的栅格到所有的生长目标点的距离,取距离最小的生长目标,为此线程对应的空白栅格的归属,转Step6。当生长目标过多时,则转Step5。
Step5:当生长目标较多时,为了减少遍历生长目标的时间,通过借鉴王新生的算法,不计算栅格点到每一个生长目标的距离,通过对空白栅格不断的进行邻域扩张,直到遇到目标生长点的方法确定此栅格的归属。
Step6将生成后的数据返回CPU端,CPU端完成栅格图像的显示与后处理。
3 实验与总结
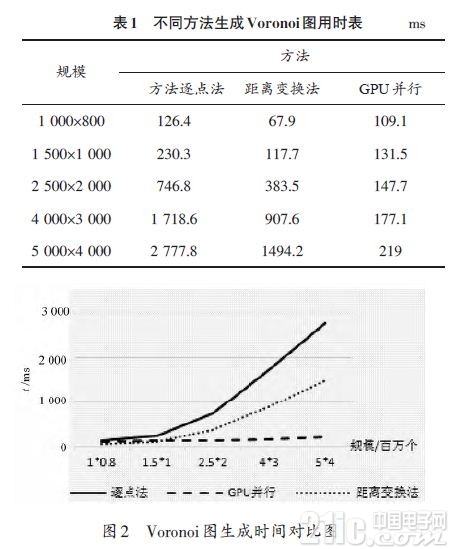
在CPU参数为IntelXeonCPUE5-2609,2.4GHz,2处理器8核心,GPU参数为TeslaC2075,448CUDA核心,显存 5.25GB的试验平台下,做了不同方法在不同栅格规模下生成Voronoi图的对比试验,试验中生长目标的个数定义为100个。由于不同的方法都采用了相同的距离定义,因此各种方法的Voronoi图生成结果都是相同的,即他们之间的生成精度是相同的,所以这里重点比较了不同方法的生成耗时。表1列出了不同方法生成Voronoi图的用时,图2为表1的折线图,从图2中可以明显看出,当栅格数量较少时,GPU并行技术的使用并不能提升生成速度,但是当栅格点数量增加时,逐点法和距离变换法用时明显增加,但GPU并行算法用时几乎不变。
4 结语
通过实验结果可以看出,采用GPU对Voronoi图的生成进行并行加速,能够很好的提高生成速度。其生成Voronoi图所需时间与只与生长目标的数量有关,而与栅格规模没有关系,当生长目标数量为n时,其时间复杂度近似于O(n),为线性的生成时间。相对于前面的几种CPU下串行算法,尤其是在栅格规模过大的情况下,能够很好的提高Voronoi图的生成速度。








评论