
2080亿晶体管,英伟达推出最强AI芯片GB200
目前,英伟达位居人工智能世界之巅,拥有人人都想要的数据中心 GPU。其 Hopper H100 和 GH200 Grace Hopper 超级芯片需求量很大,为世界上许多最强大的超级计算机提供动力。
本文引用地址://m.amcfsurvey.com/article/202403/456553.htm今天,首席执行官黄仁勋投下了 Blackwell B200 炸弹,这是下一代数据中心和 AI GPU,将提供计算能力的巨大代际飞跃。
Blackwell 架构和 B200 GPU 取代了 H100/H200。Blackwell 包含三个部分:B100、B200 和 Grace-Blackwell Superchip (GB200)。
新一代人工智能芯片 BLACKWELL GPU

新的 B200 GPU 拥有 2080 亿个晶体管,可提供高达 20petaflops 的 FP4 算力,而 GB200 将两个 GPU 和一个 Grace CPU 结合在一起,可为 LLM 推理工作负载提供 30 倍的性能,同时还可能大大提高效率。英伟达表示,与 H100 相比,它的成本和能耗"最多可降低 25 倍"。
英伟达声称,训练一个 1.8 万亿个参数的模型以前需要 8000 个 Hopper GPU 和 15 兆瓦的电力。如今,2000 个 Blackwell GPU 就能完成这项工作,耗电量仅为 4 兆瓦。
在具有 1750 亿个参数的 GPT-3 LLM 基准测试中,GB200 的性能是 H100 的 7 倍,而英伟达称其训练速度是 H100 的 4 倍。
Blackwell B200 并不是传统意义上的单一 GPU。相反,它由两个紧密耦合的芯片组成,尽管根据英伟达的说法,它们确实充当一个统一的 CUDA GPU。这两个芯片通过 10 TB/s NV-HBI(英伟达高带宽接口)连接进行连接,以确保它们能够作为单个完全一致的芯片正常运行。
这种双芯片配置的原因很简单:Blackwell B200 将使用台积电的 4NP 工艺节点,这是现有 Hopper H100 和 Ada Lovelace 架构 GPU 使用的 4N 工艺的改进版本。

B200 将使用两个全标线尺寸的芯片,每个芯片都有四个 HMB3e 堆栈,每个堆栈容量为 24GB,每个堆栈在 1024 位接口上具有 1 TB/s 的带宽。
英伟达 NVLINK 7.2T
AI 和 HPC 工作负载的一大限制因素是不同节点之间通信的多节点互连带宽。随着 GPU 数量的增加,通信成为严重的瓶颈,占用的资源和时间高达 60%。通过 B200,英伟达推出了第五代 NVLink 和 NVLink Switch 7.2T。
新的 NVLink 芯片具有 1.8 TB/s 的全对全双向带宽,支持 576 个 GPU NVLink 域。它是在同一台积电 4NP 节点上制造的 500 亿个晶体管芯片。该芯片还支持 3.6 teraflops 的 Sharp v4 片上网络计算,这有助于高效处理更大的模型。

上一代支持高达 100 GB/s 的 HDR InfiniBand 带宽,因此这是带宽的巨大飞跃。与 H100 多节点互连相比,新的 NVSwitch 速度提高了 18 倍。这应该能够显著改善更大的万亿参数模型人工智能网络的扩展性。
与此相关的是,每个 Blackwell GPU 都配备了 18 个第五代 NVLink 连接。这是 H100 链接数量的十八倍。每个链路提供 50 GB/s 的双向带宽,或每个链路 100 GB/s
英伟达 B200 NVL72

将以上内容组合在一起,您就得到了英伟达的新 GB200 NVL72 系统。
这些基本上是一个全机架解决方案,具有 18 台 1U 服务器,每台服务器都有两个 GB200 超级芯片。然而,在 GB200 超级芯片的构成方面,与上一代相比存在一些差异。图像和规格表明,两个 B200 GPU 与单个 Grace CPU 相匹配,而 GH100 使用较小的解决方案,将单个 Grace CPU 与单个 H100 GPU 放在一起。
最终结果是 GB200 超级芯片计算托盘将配备两个 Grace CPU 和四个 B200 GPU,具有 80 petaflops 的 FP4 AI 推理性能和 40 petaflops 的 FP8 AI 训练性能。这些是液冷 1U 服务器,它们占据了机架中提供的典型 42 个单位空间的很大一部分。
除了 GB200 超级芯片计算托盘外,GB200 NVL72 还将配备 NVLink 交换机托盘。这些也是 1U 液冷托盘,每个托盘有两个 NVLink 交换机,每个机架有 9 个这样的托盘。每个托盘提供 14.4 TB/s 的总带宽,加上前面提到的 Sharp v4 计算。
总的来说,GB200 NVL72 拥有 36 个 Grace CPU 和 72 个 Blackwell GPU,具有 720 petaflops 的 FP8 和 1,440 petaflops 的 FP4 计算能力。多节点带宽为 130 TB/s,英伟达表示 NVL72 可以为 AI LLM 处理多达 27 万亿个参数模型。
英伟达表示,亚马逊、Google、微软和甲骨文都已计划在其云服务产品中提供 NVL72 机架。
Blackwell 平台表现如何?
虽然英伟达在人工智能基础设施市场占据主导地位,但它并不是唯一一家在行动的公司,英特尔和 AMD 推出新的 Gaudi 和 Instinct 加速器、云提供商推动定制芯片,以及像 Cerebras 和 Samba Nova 这样的人工智能初创公司都在争夺 AI 市场的一杯羹。
预计到 2024 年,人工智能加速器的需求将远远超过供应,赢得份额并不总是意味着拥有更快的芯片,而仅仅意味着拥有可交付的芯片。
虽然我们对英特尔即将推出的 Guadi 3 芯片还知之甚少,但我们可以将其与 AMD 去年 12 月推出的 MI300X GPU 进行一些比较。
MI300X 使用先进的封装将八个 CDNA 3 计算单元垂直堆叠到四个 I/O 芯片上,从而在 GPU 和 192GB HBM3 内存之间提供高速通信。
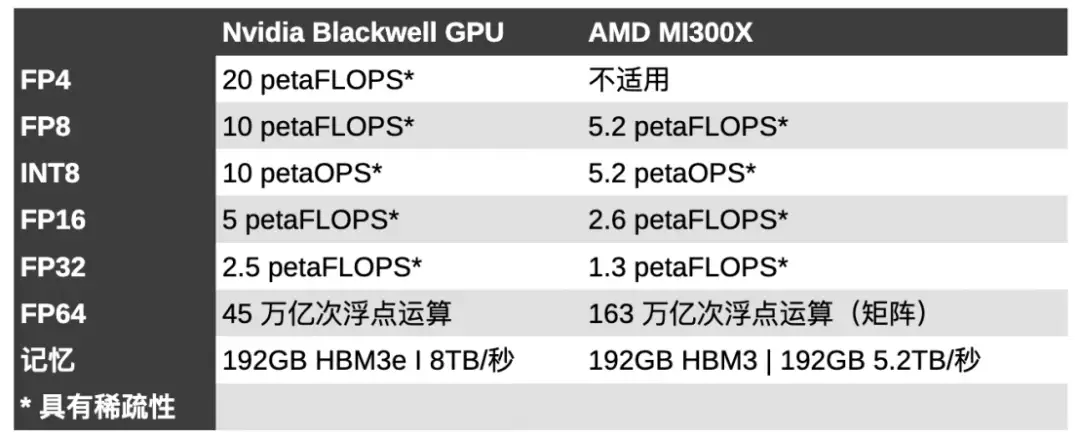
在性能方面,与英伟达的 H100 相比,MI300X 在 FP8 浮点计算方面具有 30% 的性能优势,在以 HPC 为中心的双精度工作负载方面具有近 2.5 倍的领先优势。
将 750W MI300X 与 700W B100 进行比较,英伟达芯片的稀疏性能快了 2.67 倍。虽然这两款芯片现在都配备了 192 GB 高带宽内存,但 Blackwell 部分的内存速度快了 2.8 TB/s。
内存带宽已被证明是人工智能性能的主要指标,特别是在推理方面。英伟达的 H200 本质上是带宽增强的 H100。然而,尽管与 H100 的 FLOPS 相同,英伟达声称在 Meta 的 Llama 2 70B 等模型中速度是 H100 的两倍。
虽然英伟达在较低精度方面拥有明显领先优势,但这可能是以牺牲双精度性能为代价的,而双精度性能是 AMD 近年来表现出色的领域,赢得了多个备受瞩目的超级计算机奖项。
据英伟达称,Blackwell GPU 能够提供 45 teraFLOPS 的 FP64 张量核心性能。这与 H100 提供的 67 teraFLOPS FP64 矩阵性能相比略有下降,并且与 AMD 的 MI300X(81.7 teraFLOPS FP64 矢量和 163 teraFLOPS FP64 矩阵)相比处于劣势。
还有 Cerebras,它最近展示了其第三代 Waferscale AI 加速器。怪物 90 万核心处理器只有餐盘大小,专为 AI 训练而设计。
Cerebras 声称这些芯片中的每一个都可以在 23kW 的功率下实现 125 petaFLOPS 的高度稀疏 FP16 性能。Cerebras 表示,与 H100 相比,该芯片在半精度下速度快了约 62 倍。
然而,将 WSE-3 与英伟达的旗舰 Blackwell 部件进行比较,领先优势大幅缩小。据我们了解,英伟达的顶级规格芯片应能提供约 5 petaFLOPS 的稀疏 FP16 性能。这将 Cerebra 的领先优势缩小至 25 倍。但正如我们当时指出的那样,所有这一切都取决于您的模型能否利用稀疏性。
台积电和 Synopsys 正推进部署使用英伟达的计算光刻平台
英伟达今天宣布,台积电和 Synopsys 将使用英伟达的计算光刻平台投入生产,以加速制造并突破下一代先进半导体芯片的物理极限。
全球领先的代工厂台积电 (TSMC) 和芯片到系统设计解决方案的领导者新思科技 ( Synopsys) 已将英伟达 cuLitho 与其软件、制造工艺和系统集成,以加快芯片制造速度,并在未来支持最新一代 英伟达 Blackwell 架构 GPU。
英伟达创始人兼首席执行官黄仁勋表示:「计算光刻是芯片制造的基石。」「我们与台积电和新思科技合作,在 cuLitho 上开展工作,应用加速计算和生成式 AI 来开辟半导体缩放的新领域。」
英伟达还推出了新的生成式 AI 算法,增强了 cuLitho(GPU 加速计算光刻库),与当前基于 CPU 的方法相比,显著改进了半导体制造工艺。
计算光刻是半导体制造过程中计算最密集的工作负载,每年在 CPU 上消耗数百亿小时。芯片的典型掩模组(其生产的关键步骤)可能需要 3000 万小时或更多小时的 CPU 计算时间,因此需要在半导体代工厂内建立大型数据中心。通过加速计算,350 个 英伟达 H100 系统现在可以取代 40,000 个 CPU 系统,加快生产时间,同时降低成本、空间和功耗。
台积电首席执行官 CC Wei 博士表示:「我们与英伟达合作,将 GPU 加速计算集成到台积电工作流程中,从而实现了性能的巨大飞跃、吞吐量的显著提高、周期时间的缩短以及功耗要求的降低。」「我们正在将 英伟达 cuLitho 转移到台积电生产,利用这种计算光刻技术来驱动半导体微缩的关键组件。」
自去年推出以来,cuLitho 使台积电为创新图案技术开辟了新的机遇。在共享工作流程上测试 cuLitho 时,两家公司共同实现了曲线流程的 45 倍加速以及传统曼哈顿式流程近 60 倍的改进。这两种类型的流不同,对于曲线,掩模形状由曲线表示,而曼哈顿掩模形状被限制为水平或垂直。
Synopsys 总裁兼首席执行官 Sassine Ghazi 表示:「二十多年来,Synopsys Proteus 掩模合成软件产品一直是加速计算光刻(半导体制造中要求最高的工作负载)的经过生产验证的选择。」「随着向先进节点的转变,计算光刻的复杂性和计算成本急剧增加。我们与台积电和 英伟达的合作对于实现埃级扩展至关重要,因为我们开创了先进技术,通过加速计算的力量将周转时间缩短了几个数量级。」





评论