
高速数据流盘处理:编程与标定
数据流盘应用的最优方法
应用从单线程到多线程架构的演进被广泛认为是重大的编程挑战。LabVIEW为多核处理器提供了一个理想的编程环境,因为LabVIEW应用在本质上是多线程的。因而,LabVIEW编程人员通过几乎很少甚至无需额外的编码,便可以从多核处理器获益。多线程应用程序非常适用于并行测试和数据流盘应用,而且,在流处理应用中运用适当的编程技术,可以使PXIExpress仪器发挥最大性能,这是通过代码的并行化完成的。
同样,并行机制还可以应用于创建数据流盘应用或从计算机处理器获取最大性能。在流盘应用中,两个主要占用总线和处理器的任务是:1)从数字化仪采集数据,和2)将数据写入到文件中。由于这一点是事先知道的,所以进程可以划分为多个循环。利用LabVIEW队列机构,每个循环间实现了数据共享。通常,这被称为一个生产者-消费者算法结构。
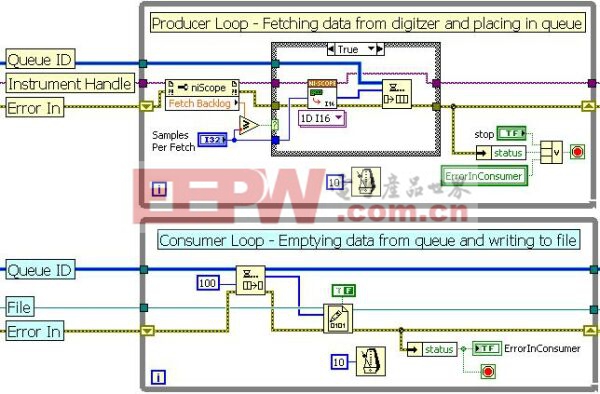
图2:带有队列结构的生产者/消费者循环架构。
在上例中,上面的循环(生产者)从一个高速数字化仪中采集数据,并将其传递至一个队列。下面的循环(消费者)从队列中读取数据并将其写入到磁盘。在后台,LabVIEW为队列在PC中分配一个存储块。该存储器模块被用作两个循环间数据传递的临时存储FIFO。对于大多数编程语言,多个进程间的存储器共享要求不菲的编程开销。然而,LabVIEW处理了所有的存储器访问,以确保读-写竞争状况不会发生。队列结构的执行可以通过下图可视化展示:
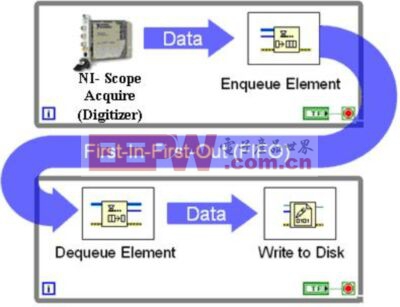
图3:对列结构的数据流编程模型。











评论