
GPU如何工作:PowerVR/高通Adreno/ARM Mali的渲染模式分析
TBDR是如何实现HSR的呢?
本文引用地址://m.amcfsurvey.com/article/201606/292810.htm不过几何体压缩并非TBDR的卖点,TBDR的真正卖点是可以实现完全消除不可见三角形的片元渲染,那么它是如何做到这一点的呢?

(Kristof Beets)
根据现在供职于ImgTec担任商业开发总监的Kristof Beets在 2001年(就在这一年他加盟PowerVR,任职开发者关系协调工程师,该文似乎是他在PowerVR实习期间撰写的)的一篇文章,PowerVR的HSR实现方式应该是这样的:
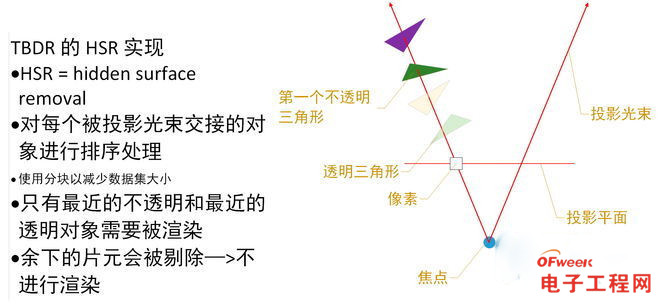
1、从Tile Buffer中获得第一个指针,基于这个指针就能拾取到Scene Buffer中所有三角形的数据。
这一步可以实现预拾取并将数据存放在一个GPU的片上缓存里,这个高速缓存可以称作为On-Chip Tile buffer(片上块元缓存),用作区别于片外的图元列表Tile Buffer,虽然都是块元缓存,都是对应16*16个像素,但是存放的东西完全不一样(一个是从指针解引用后获得的三角形数据和计算好的深度值,另一个则是图元列表)。
2、使用这个三角形的数据计算出被该三角形覆盖的Tile中每个像素的Z值(深度值)。
3、这些深度值数据以及对应于第一个三角形的指针被一起存放在GPU内的高速缓存里。
4、重复上面的步骤,获得第二个三角形的数据以及该Tile中被其覆盖的像素的深度值,对第二个三角形覆所盖像素的深度值和第一个三角形所覆盖像素的深度值进行比较,如果新的深度值更接近于视口(表明是可看见的),就更新深度值以及三角形(指向新的三角形)。
5、重复上述的步骤,直到覆盖该Tile的所有三角形数据以及深度信息更新完毕。
6、此时,GPU的片上高速缓存存放的就是用于确定像素色彩的三角形。
前面的Scene Buffer以及Tile Buffers都是存放在GPU外的,而上面步骤中绝大部分操作都是GPU内部的高速缓存上进行的(除了从Scene Buffer中载入该块元的三角形数据外),速度会非常快。
渲染一个块元需时256个周期(根据Kristof Beets文章提到16x32的块元需时512个周期推算):
1、数据拾取可以采用流水线结构,因此不存在性能惩罚;
2、筛选(计算Z值)需时一个周期,这个步骤也可以采用流水线结构,每个三角形的检查和块元更新可以在一个周期内完成。
因此除非时出现极端状况,256个周期的渲染时间是可以掩盖掉块元中含有256个三角形执行筛选动作的耗时,在一个16x16的块元内出现256个三角形的情况目前来说应该还是很少见。
按照这样的思路可以推算出 1920x1080 60FPS下能实现的每秒三角形筛选能力是:
1920x1080 * 60FPS = 124,416,000 Mtriangles/s
根据上面的算式可以得出在像PowerVR SGX 5上每个块元含有高达256个三角形的情况下,要满足60FPS速率时的三角形筛选个数为124百万三角形,现实的游戏中几乎没有这样的情况会出现,因为目前的制程无法做到一个全程胜任这个三角形规模真实游戏的移动GPU。
在知名的三维性能测试软件3DMark里有一个支持在手机上进行测试的icestorm场景,其三角形规模在Extreme模式时候的为每帧28,000个,达到60FPS时就是每秒1.68百万三角形/秒,对于手机来说这个测试已经算是比较严苛了,但是此时三角形规模也就是每个块元大约3.5个三角形,远远低于每周期256个三角形的处理能力。
PowerVR的渲染
完成块元渲染后,在块元帧缓存中的数据会被写入到显存(在手机中通常显存和系统内存共享)中。在这个写入动作执行的时候,会一并执行抖动操作(只执行一次而非多次)。如果在台PC上,如果指定了超取样抗锯齿,在这一步还会执行一个向下取样的操作,将画面缩小到指定的屏幕分辨率。
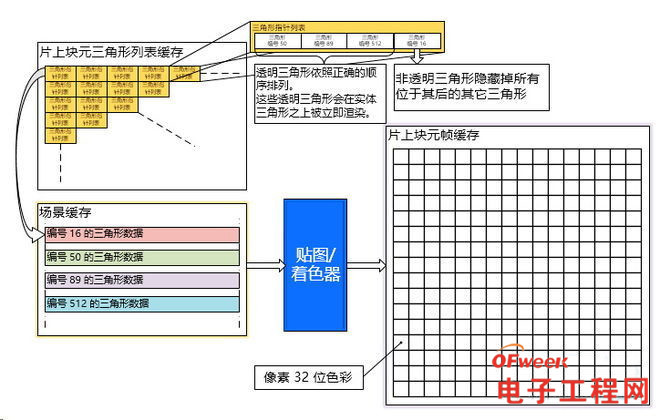
在完成了一个块元的渲染后,这个块元的像素会被传输到显存(对于采用一体内存架构的移动设备来说,这块显存是从主内存中分配的)。
然后,GPU继续下一个块元的渲染,直到整帧画面渲染完毕后,以双缓存方式运作的Scene Buffer开始把下一帧的块元递交给渲染单元执行后续工位处理,周而复始。
相较于非TBDR的GPU微架构来说,PowerVR或者说TBDR能对整个画面(场景)进行判别,确定哪些三角形覆盖的片元需要渲染,而“传统”的立即渲染架构无法实现这一点。
Kristof Beets的原文还介绍了infinite plane(无限大平面)和HSR的关系,所谓的infinite plane并不难理解,你可以想象一下:在一个三维空间里存在着一块无限大的平面,这块平面显然会把这个三维空间一分为二。
如果我们在这个三维空间多弄几个这样的平面并使其相交,也就可以构建出一个几何体模型出来了(例如只要六个相交的无限大平面就能构造出一个多边形数很少的立方体)。

这样的建模技术和常见的三角形建模是有很大区别的,所以很难找到合适的建模工具,其应用非常受限,而且随着模型越来越复杂,无限大平面的优势也就没啥感觉了(在Youtube上有一段采用PowerVR PCX2渲染一个由35个无限大平面构建的甜甜圈的视频,帧率只有47 fps),三角形此时是更合理的选择。
好好的三角形不用,为啥要折腾这个无限大平面呢?可能的原因是在当时看来,这样的技术可以节省在Scene Buffer里要存放的三角形数:
在几何阶段,PowerVR会根据从视点发出的一条“测量光”确定最前和最后的平面相交点,藉此得出一个渲染计算约束椎体(effect volume),使得这些无限大平面变成有限的平面,加上隐面消除技术,几何体外突出的平面也被消隐掉。
较少的多边形、可以和TBDR的隐面消除技术完美配合,于是无限大平面建模的合理性也就因此存在了。
据说在PowerVR Series 2以后就不在支持无限大平面,目前为止只有世嘉 DreamCast中的那枚PowerVR芯片是具备无限大平面建模能力的图形芯片,所以无限大平面这个部分我们完全不需要考虑,这里介绍主要是为了强调一下 PowerVR的特点——近乎完美的隐面消除能力(如果不涉及阿尔法混合、阿尔法测试的话,因为这两项操作会导致HSR失效)。
我们上面费了很多口舌来阐述PowerVR的最主要特色TBDR,接下来就让我们说说当前以及即将推出的PowerVR GPU到底会长成什么样子。
ImgTec PowerVR Rogue
ImgTec在2012年发布了名为PowerVR Rogue的第六代PowerVR微架构,现在市场上许多手机里的GPU都是基于该微架构的变种,例如红米Note 3/Note2、魅蓝 Metal、魅族 MX5里的PowerVR G6200。苹果iPhone 6s Plus的GPU经过各种验尸手段查证后确认为PowerVR GT7600,这个GT7600被PowerVR定义为第七代PowerVR(PowerVR Series 7 或者 Rogue 7)微架构。毫无疑问,不论档次高低,现在许多手机、平板电脑中都有基于PowerVR的GPU。

ImgTec属于经营、开发知识产权的芯片公司,本身并不直接售卖芯片,透过研发大量芯片内核,然后将其授权给需要的第三方公司,收取授权金来维持公司的运营,因此他们会弄一大堆内核,以满足不同厂商、市场的需求。
理论上这样的运管方式只牵涉到研发费用和市场拓展费用,弄一大堆内核IP的并不会造成实体产品那样的库存压力。
ImgTec在2012年发布了代号Rogue的PowerVR Series6微架构,最低端的是G60X0和G61X0(x为其中一个数字编号,不同编号型号配置均不一样),对应的D3D规格只能够支持DX9特性级别。
在型号的含义方面,G6050里有0.5个正常规格的USC(通用着色器簇),61X0 里含有1个USC。USC 是PowerVR Series 6引入的统一着色簇简称,区别于以往的PowerVR Series 5时候的USSE。
前面我们所说的TBDR是指渲染流程的方式,而通用着色器簇则是指具体微架构里将若干个计算、贴图部件绑定在一起的单元,一个USC 就类似于CPU中传统概念上的一个内核,正如我们前面所说的,它对应的就是通用计算标准OpenCL中的术语就是Compute Unit。
下图是PowerVR最新的PowerVR Series 7XT的微架构图:
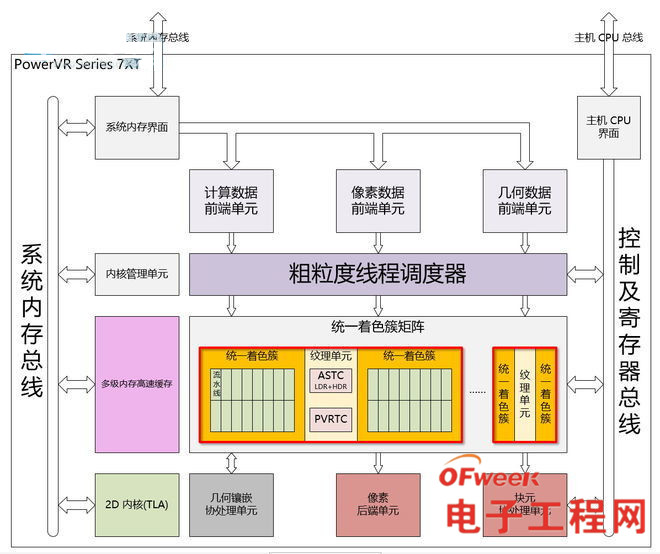
GPU厂商在设计GPU的时候都会把延伸性作为重要的设计因素,因为这样能确保软件、硬件资源的最充分利用,上图的USC规模可以依据具体的应用情况作调整,例如iPhone 6s采用的GT7600就具备6个USC(或者说6个CU)。
上图的PowerVR Series 7XT属于目前ImgTec最强大的GPU微架构,苹果公司的iPhone 6s列就是采用基于该GPU微架构的GT7600。
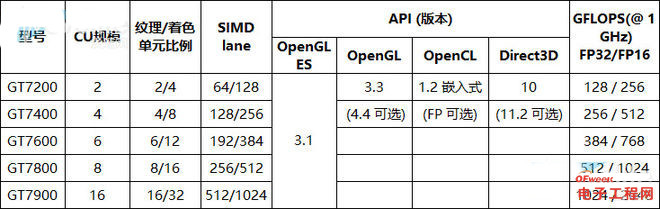
作为PowerV RSeries 7的GT7600,提供了FP16(半精度)的原生支持,所以如果程序采用了FP16的话,性能会较FP32快一倍,对于手机应用来说,FP16 提供了10位的有效值和5位的指数,是可以满足许多情况下的图形渲染计算的需求。
要正确使用这类FP16需要比FP32更多的技巧,像当年NVIDIA的NV3X就提供了FP32 + FP16设计,但是在和AMD R300的性能竞争中一直处于下风,维持NV3X拉力的主要靠NVIDIA和各个游戏开发商紧密的合作关系。
上表中的GFLOPS指标是指GPU计算单元运行于1GHz时候的情况,不过我们目前尚未有可靠的iPhone 6s系列GPU运行频率规格,wiki百科上写的苹果A9 GPU为450MHz(此时的单精度浮点性能是172 GFLOPS)或者533MHz也只能是参考。
根据GFXBench的ALU测试结果,iPhone6s Plus(GT7600,6 USC)是 12781fps,iPhone6 Plus(GX6450,4 USC)是5847 fps,这意味着前者的计算性能是后者的两倍左右,考虑到ImgTec曾经表示PowerVR Series 7XT浮点性能在同频、同规模下的性能是PowerVRSeries 6XT 1.6 倍,这个测试结果表明iPhone 6s Plus的GT7600频率很可能和iPhone 6 Plus的GX6450相当。
业界也有人认为iPhone 6s系A9采用的并非GT7600,原因是开发文档缺乏一些PowerVR Series 7XT存在的Tessellation等特性以及采用Metal作为API,这其实因为PowerVR的授权本来就允许厂商自行定制驱动,像 Intel的GMA系列GPU就没有开放TBDR这样的PowerVR最核心技术,而且Tessellation对于这个级别的GPU而言意义也不是很大(有多少人用过iPhone 6 GX6450里的那个Tessellation?),所以不必太为此纠结。



评论