
GPU如何工作:PowerVR/高通Adreno/ARM Mali的渲染模式分析
在渲染片元的时候,GPU先比较最粗糙版本的Z-buffer。如果要画的片元Z值还比较远,那这个片元就一定不用画出来了。如果它比较近,就再拿比较细的Z-buffer来比较,一直比较到最细的版本。在理想的情形下,通常大部分的片元都不需要比较到最细的版本,所以可以节省不少时间(要记得,一个“粗糙”版的Z值比较,其实就等于和四个“精细”版的 Z 值比较)。
本文引用地址://m.amcfsurvey.com/article/201606/292810.htm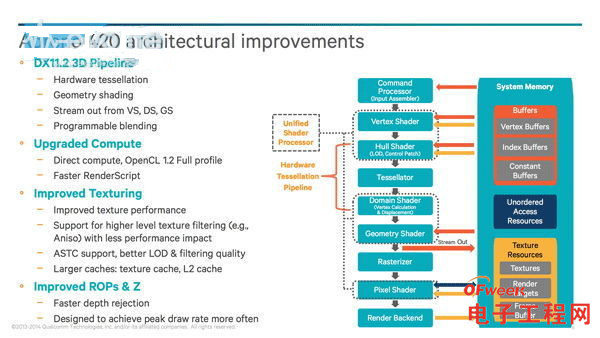
相较之下,PowerVR的TBDR会在几何阶段的三角形裁剪后将当前 scene(场景或者说画面)的三角形经过筛选排序存放在scene buffer 内,然后由 HSR(隐面消除)算法将摄像机视点不可见的片元剔去掉,这部分实现细节已经在PowerVR一节中有阐述,这里就不再复述了。
按照高通的说法,Adreno从3xx系列采用了名为FlexRender的渲染架构,可以自动在立即渲染和TBDR之间切换,而且这个TBDR的执行过程和PowerVRTBDR是基本一样的(同样有对三角形进行binning和剔除无效片元的处理):
所以从微架构方面而言,高通透露的信息并不多,只能看到个大概,以骁龙820搭配的Adreno530为例,采用了统一着色架构和FlexRender,配有256个ALU,支持DirectX 12.1、Vulkan、OpenCL 2.0。

采用骁龙820(搭载Adreno530)的小米 5(价格1999元版本))在运行OpenCL-Z的FP32 性能测试结果是287 GFLOPS,相较之下,价格799元的红米Note 2(Power VR 6200)只有44 GFLOPS,前者是后者性能的6.52倍,当然,这个测试只是属于底层测试,实际的游戏体验因人、因应用而异。
安谋Mali——弱核化设计
安谋(ARM)最为人熟知的是旗下的各款 ARM CPU内核,目前的主要手机几乎都是采用ARM 阵营的CPU。
ARM的GPU Mali是ARM在2006年收购的挪威公司Falanx获得的,源起于是90年代由ARM在挪威科技大学支持的的项目,到了2001年由Borgar Ljosland与四位在该项目中的GPU团队学生于2001年创办了这家Falanx Microsystems。
Falanx最初是希望打进台式机市场,不过随着3dfx、Matrox等公司的萎靡、败退,台式机GPU市场的格局发生了很大的变化,不再有空间给新丁了,Falanx转向了从事手机、PDA、机顶盒、游戏掌机、信息机等领域,不过他们当时在这个领域其实做得并不算很出色,ARM的收购对他们来说是一个重要的转折点。

ARM收购Falanx推出的第一款GPU就是2007年的Mali-200,是Mali第一款OpenGL ES 2.0 GPU,它和它的换代型号Mali-300、Mali-400、Mali-450都是基于名为Utgard(北欧神话中Utgard-Loki统治下约顿巨人位于仙宫与尘世之外的宫殿)的微架构。Utgar采用的是非统一架构,顶点指令和像素指令有各自专门的单元来执行,到了Mali-400时候实现了多核能力。
Mali最新的微架构代号是Midgard,和Utgard不同的是,Midgard开始采用统一着色架构,几何和片元操作指令都在同一个着色器单元上执行。
Mali同样采用了分块式渲染(块元大小是16x16),但是根据下面这个幻灯片,可以看到其scene buffer或者说primitive buffer保存的图元顺序必须和程序递交的顺序保持一致(画红线部分),不存在PowerVR那样的筛选(sorting)动作。
因此如果按照ImgTec的说法 Mali并不能算是真正的TBDR,当然,它还是具备 Early-Z这样的隐面消除能力,只是粒度上肯定不如PowerVR那么细(PowerVR自称其HSR能力为pixel perfect)。

在渲染流程方面,Mali或者说Midgard和目前你看到的大多数GPU做法有些不一样,那就是作为统一渲染架构,它可以在同一时间里同时对几何和片元进行渲染操作,而其他的GPU在同一时间里要嘛就是几何计算要嘛就是片元计算:

如上图所示,你可以看到Mali可以在同一时间片上同时进行几何和片元操作,这表明Mali内部的任务调度设计非常灵活,原因请看下面的介绍。
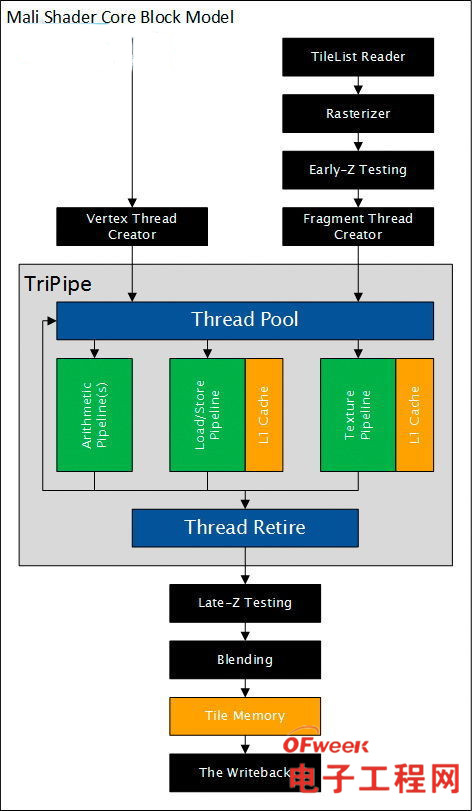
上图是Mali的着色器内核(Shader Core)功能模块图,可以看到,如果图示的确是正确的话,那么这个着色器内核里面可谓是五脏俱全,本质上就是一个小 GPU,图形渲染所涉及到的操作都能在一个 Shader Core 上完成,因此配有多个Shader Core的Mali可以做到在同一时间内跑几何和片元处理,多个Shader Core的Mali GPU其实就是一个片上多GPU并行渲染系统。
其实其他厂商尤其是采用TBR的GPU可以像Mali这样片上多核运行多个Tile,但是Mali GPU的特别之处是它的内核内部是没考虑扩展的,至少目前是这样。像ImgTecPower VR XT7等其他厂牌的GPU内部的CU数都是具备延伸能力的,而Mali GPU则对不起,不管什么型号的Mali GPU,上面的Tri-Pipe 都是固定的一个,这就是所谓的“完整的弱内核”设计。
从OpenCL的角度而言,每个Mali内核都是一个CU,只能以多个Partition(分区)的方式实现规模扩张。而像PowerVR则是既可以多个CU 也可以多个Partition的方式实现规模上的性能延伸。

值得一提的是,Mali-T880的Tri-Pipe,这其实就是Mali的可编程渲染/计算单元,其中包含了纹理(T-Pipe)、内存指令(LS-Pipe)和算术逻辑(A-Pipe)单元三部分,在Mali-T880之前,Tri-Pipe的算术逻辑单元大都只有两个,而在Mali-T880上,Tri-Pipe 的算术逻辑单元增加到了3个,使其计算能力提升了50%。
Mali相对于目前大多数其他厂商GPU的另一个区别要点是它的A-Pipe采用了SIMD向量处理设计,寄存器能够像目前CPU的SIMD单元那样灵活地拆分成2xFP64、4xFP32、8xFP16、2xInt64、4xInt32、8xInt16、16xInt8等数据类型访问。
按照ARM的说法,Mali的算术ISA 用了SIMD + VLIW的设计:
三个向量单元(128-bit数据路径)
4路FP32或者8路FP16
16路Int8
两个标量单元(32-bit数据路径)
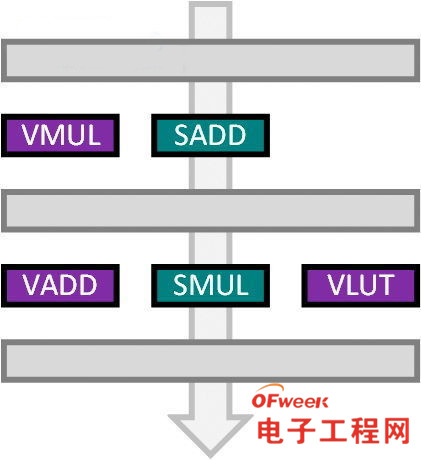
按照ARM官方博客的一篇文章,Mali-T760的每条A-Pipe单周期单精度计算性能是17FLOP,从上图来看,VMUL和VADD以及SADD、SMUL的FLOPS是应该是10个,余下的7个就是那个VLUT。
LUT的含义并不是很清楚,也许是查表(Look-up Table)的含义,不过这样的话,我觉得似乎不太适合将其归入到人们常说的通用计算性能指标里,即使其使用的是VLIW指令集。
所以我觉得每条A-Pipe的单精度性能应该视作每周期10个比较合适。对于Mali-T880MP16来说,在 650MHz 时候的单精度性能应该是312 GFLOPS,同理,Mali-T760MP8的单精度浮点性能应该是104 GFLOPS,当然这只是我的个人意见。
LS-Pipe执行的是和纹理无关的内存存取动作,例如几何/片元处理时候的属性读取和变量写入操作。通常而言每条指令就是一次内存访问操作,如果是 A-pipe的向量操作就是单指令Vec4操作。
虽然ARM Mali并非TBDR,不具备在进入块元渲染之前透过筛选将无效的片元剔除掉,但是它的某些型号具备名为Forward Pixel Kill(正向像素剔除,简称FPK,见上面Mali-T880 Shader Core架构图中Early-Z后接的就是FPK单元)技术。
具备这个技术的GPU所跑的线程不再是不可撤销的,如果发现稍后的线程要向相同像素位置写入不透明数据,就会将已经在进行的计算终止掉。由于每个像素需要花费一段时间才能完成,因此 FPK可以有一个时间窗口来排空流水线中已有的无效渲染片元。
按照ARM的说法,这个FPK技术在最适中的流水时间窗口下所能达到的消除无效渲染效果可以和PowerVRTBDR w/HSR媲美,而且无需对整个画面的三角形进行筛选、无需在程序里添加筛选代码、能够对半透明对象实行正确处理、不会对帧率产生突变影响。

上面这个表格是维基百科上的Mali各型号规格表,其中的单精度指标是包括了那个VLUT的。
目前市场上大多数采用Mali的中端SoC都还是基于Mali-4XX系列,按照 ARM的说法,目前有75%的数字电视、超过50%的Android平板电脑、大于35% 的智能手机采用了Mali GPU。
例如小米电视3就采用了Mali-T760MP4这个GPU,三星去年的旗舰产品Galaxy S6、Galaxy S6 Edge都有采用Mali-T760,我手头有一台支持智能卡的电信T6有线电视机顶盒,搭配的是全志的SoC,其中的GPU也是ARM Mali-400MP,所以这个看上去有点古怪(完整的弱内核设计)的GPU在市占率方面Mali已经取得了相当不错的成绩。
三星Galaxy S6采用的Mali-T760MP8名义频率是772MHz,理论单精度性能是123.5 GFLOPS(按照每个算术流水线里包含两个4 路FP32 SIMD和两个 FP32标量来统计,未将那个相当于7个FLOPS 的VLUT或者说 SFU 单元计算在内),3DMark Ice Storm Unlimited 得分是 20988 ,而采用PowerVRGT7600的iPhone 6s Plus 3Dmark Ice Storm Unlimited 结果是27811,基本上符合123.5 GFLOPS vs 172.8GFLOPS (按照iPhone 6s Plus的GT7600频率为450MHz时计算出的单精度性能为172.8 GFLOPS)的差距。
我们相信,在新的一年里将有机会看到Mali-T8xx系列初露峥嵘,原因是Mali的完整弱内核比较便于随意搭配,新内核带来的规格、性能提升也可以为新应用带来更好的用户体验。
结语
在这篇文章里,我们介绍了三个常见的智能设备或者说手机/平板电脑的GPU,涉及到的知识面相对坊间的大多数文章而言要更深入一些,例如ImgTec的PowerVR、高通的Adreno、ARM的Mali虽然都属于TBR,但是具体的实现却有着各自的特色。

ImgTec的PowerVR是三个TBR架构中历史最长的,也是10年GPU大战中少数幸存下来并且活的还比较滋润的厂商之一,PowerVR在TBDR方面拥有非常丰富的实作经验,凭借 TBDR 的高能效比特点,在移动设备中站稳了脚跟,成为包括苹果在内众多手机厂商选择的GPU方案。
高通的 Adreno 从3xx系列开始引入了名为FlexRender的渲染技术,能动态在IMR和TBDR渲染模式之间切换,前者可以在兼容性、响应时延方面提供最佳的保证,而后者可以在性能耗电比方面达到更佳的体验效果。
Mali的渲染架构相对简单,属于TBIMR,也就是分块式立即渲染,对递交的三角形顺序不作筛选处理,分块的主要目的是节省带宽,不过它的某些型号具备名为 Forward Pixel Kill的技术,能够随时停掉“预见”到的无效像素(线程)的渲染,号称可以达到媲美PowerVR TBDR 的效果。同时,Mali采用了“完整弱GPU内核”(相对于其他厂商的“完整可延伸GPU内核”而言)设计,内核中的渲染单元不能扩展,性能的规模延伸是透过增加内核数来达到。
我们在本文中没有对NVIDIA的GeForce ULP和Intel的GenX进行介绍,不过它们其实基本上就是同架构的台式机版本的规模缩减版,当然,由于针对的移动设备,其中还有一些省电措施,遗憾的是,这两家厂商的GPU虽然性能不错,但是在手机市场上由于各自自身的因素而缺乏整机厂商的支持。
所以,本文从一开始就不打算透过这篇文章来影响读者的购买意向,这只是一篇有科普性质的文章,尽可能地较少功利的因素,但求看起来资料尽可能详细有趣同时又能增加一些见识就行。



评论