
基于DSP的高性能通用并行弹载计算机设计与实现
首先考虑共享总线结构。设
![]()
假设任务均匀分成p部分,就有:Te=pt。在最坏情况下,p个处理器总是同时访问总线,考虑最后得到总线访问权的处理器:
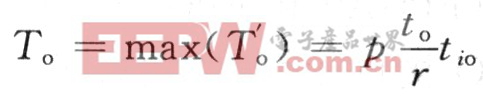
Tp是每个处理器上并行算法运行时间,在最坏情况下,Tp=Te+To。设问题规模W为最佳串行算法完成的计算量,即W=Te,加速度比:
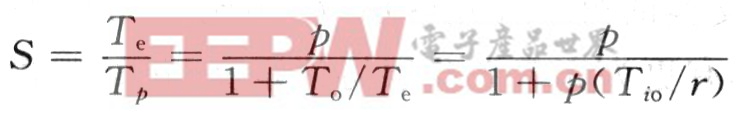
显而易见,共享总线系统的并行效率随着处理器数目p的增大而下降。
而在分布式并行系统中,理想情况下任一时刻都可有两个处理器通过其通信口相互交换数据,设一个通信口传送一个数据的相对时间为tcomm,等效为处理器运算能力和通信口传输能力之比。同时,假设每次交换还需对本地存储器访问。这样就有通信开销:

和处理规模p成线性关系,并行效率与p无关。
以上讨论的是假设任意两个处理器之间可以直接进行数据交换,而在实际情况下,尤其是处理器数目p多于处理器的通信口数量时,两个非直接相连的处理器之间的数据交换所需开销与其经过的路径成正比关系。但这并不影响以上讨论的公式。因为在规则网络拓扑结构中最大或平均路径是一个定值n,那么这时,分布式并行系统的加速比公式为:

可见,在这种情况下分布式并行系统同样能获得线性加速比。由以上理论分析可知,共享总线并行结构适合共享存储编程模型,进行细粒度的并行处理,但其扩展性能较差,处理器的数目有限,单机处理性能有限;分布式并行结构采用消息传递的机制,适合进行粗粒度的并行处理,便于大规模的系统扩展,提供强大的整体性能。
2 弹载计算机的设计实现
由于弹上信号处理算法的复杂性,信号处理系统具有复杂多样的并行处理模式,如基于空间的数据并行处理、基于时间的流水并行处理等。另外,弹上计算机系统具有多种类型的数据流,如原始数据流(A/D采集之后的数据流)、中间数据流(各处理节点之间传递的数据流)、定时同步信号以及控制数据流等。这些不同的数据流的传输带宽不同,因此系统中要有与这些不同数据流相匹配的互联网络。
高性能通用并行弹载计算机是构建信号处理系统的基础。它除了选用高性能的处理器外,为了具有通用性,还要具有标准化、模块化、可扩展、可重构的特点,以便构建各类控制和信号处理系统。同时为了适应控制和信号处理系统复杂并行处理模式和多种数据流的特点,它要具有混合的并行模式和多层次的互联网络。基于这些要求和上文中对并行处理结构模型的理论分析,笔者选用当前业界最高性能的浮点DSP芯片TS201和大规模FPGA,设计了一个标准化、模块化、可扩展、可重构、混合并行模式、多层次互联的高性能通用并行弹载计算机。图2是其结构框图。











评论