
大模型市场,不止带火HBM
近日,HBM成为芯片行业的火热话题。据 TrendForce 预测,2023 年高带宽内存(HBM)比特量预计将达到 2.9 亿 GB,同比增长约 60%,2024 年预计将进一步增长 30%。2008 年被 AMD 提出的HBM内存概念,在 2013 年被 SK 海力士通过 TSV 技术得以实现,问世 10 年后 HBM 似乎真的来到了大规模商业化的时代。
本文引用地址://m.amcfsurvey.com/article/202307/448547.htmHBM 的概念的起飞与AIGC 的火爆有直接关系。AI服务器对带宽提出了更高的要求,与 DDR SDRAM 相比,HBM 具有更高的带宽和更低的能耗。超高的带宽让 HBM 成为了高性能 GPU 的核心组件,HBM 基本是AI服务器的标配。目前,HBM 成本在 AI 服务器成本中占比排名第三,约占 9%,单机平均售价高达 18,000 美元。
自从去年ChatGPT出现以来,大模型市场就开始了高速增长,国内市场方面,百度、阿里、科大讯飞、商汤、华为等科技巨头接连宣布将训练自己的 AI 大模型。TrendForce 预测,2025 年将有 5 个相当于ChatGPT的大型 AIGC、25 个 Midjourney 的中型 AIGC 产品、80 个小型 AIGC 产品,即使是全球所需的最小计算能力资源也可能需要 145,600 至 233,700 个英伟达 A100 GPU。这些都是 HBM 的潜在增长空间。
2023 年开年以来,三星、SK 海力士 HBM 订单就快速增加,HBM 的价格也水涨船高,近期 HBM3 规格 DRAM 价格上涨了 5 倍。三星已收到 AMD 与英伟达的订单,以增加 HBM 供应。SK 海力士已着手扩建 HBM 产线,目标将 HBM 产能翻倍。韩媒报道,三星计划投资约 7.6 亿美元扩产 HBM,目标明年底之前将 HBM 产能提高一倍,公司已下达主要设备订单。
HBM 在 AIGC 中的优势
直接地说,HBM 将会让服务器的计算能力得到提升。由于短时间内处理大量数据,AI 服务器对带宽提出了更高的要求。HBM 的作用类似于数据的「中转站」,就是将使用的每一帧、每一幅图像等图像数据保存到帧缓存区中,等待 GPU 调用。与传统内存技术相比,HBM 具有更高带宽、更多 I/O 数量、更低功耗、更小尺寸,能够让 AI 服务器在数据处理量和传输速率有大幅提升。
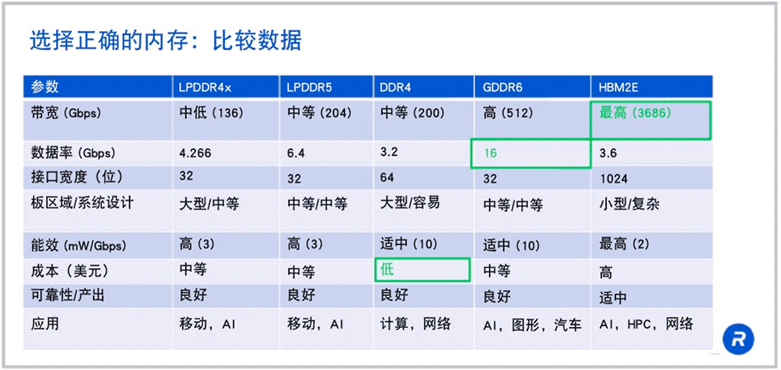
来源:rambus
可以看到 HBM 在带宽方面有着「碾压」级的优势。如果 HBM2E 在 1024 位宽接口上以 3.6Gbps 的速度运行,那么就可以得到每秒 3.7Tb 的带宽,这是 LPDDR5 或 DDR4 带宽的 18 倍以上。
除了带宽优势,HBM 可以节省面积,进而在系统中安装更多 GPU。HBM 内存由与 GPU 位于同一物理封装上的内存堆栈组成。
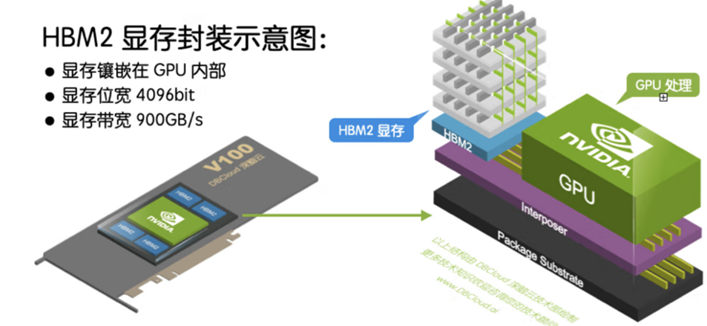
这样的架构意味着与传统的 GDDR5/6 内存设计相比,可节省大量功耗和面积,从而允许系统中安装更多 GPU。随着 HPC、AI 和数据分析数据集的规模不断增长,计算问题变得越来越复杂,GPU 内存容量和带宽也越来越大是一种必需品。H100 SXM5 GPU 通过支持 80 GB(五个堆栈)快速 HBM3 内存,提供超过 3 TB/秒的内存带宽,是 A100 内存带宽的 2 倍。
过去对于 HBM 来说,价格是一个限制因素。但现在大模型市场上正处于百家争鸣时期,对于布局大模型的巨头们来说时间就是金钱,因此「贵有贵的道理」的 HBM 成为了大模型巨头的新宠。随着高端 GPU 需求的逐步提升,HBM 开始成为 AI 服务器的标配。
目前英伟达的 A100 及 H100,各搭载达 80GB 的 HBM2e 及 HBM3,在其最新整合 CPU 及 GPU 的 Grace Hopper 芯片中,单颗芯片 HBM 搭载容量再提升 20%,达 96GB。
AMD 的 MI300 也搭配 HBM3,其中,MI300A 容量与前一代相同为 128GB,更高端 MI300X 则达 192GB,提升了 50%。
预期 Google 将于 2023 年下半年积极扩大与 Broadcom 合作开发 AISC AI 加速芯片 TPU 也计划搭载 HBM 存储器,以扩建 AI 基础设施。
存储厂商加速布局
这样的「钱景」让存储巨头们加速对 HBM 内存的布局。目前,全球前三大存储芯片制造商正将更多产能转移至生产 HBM,但由于调整产能需要时间,很难迅速增加 HBM 产量,预计未来两年 HBM 供应仍将紧张。
HBM 的市场主要还是被三大 DRAM 巨头把握。不过不同于 DRAM 市场被三星领先,SK 海力士在 HBM 市场上发展的更好。如开头所说,SK 海力士开发了第一个 HBM 产品。2023 年 4 月,SK 海力士宣布开发出首个 24GB HBM3 DRAM 产品,该产品用 TSV 技术将 12 个比现有芯片薄 40% 的单品 DRAM 芯片垂直堆叠,实现了与 16GB 产品相同的高度。同时,SK 海力士计划在 2023 年下半年准备具备 8Gbps 数据传输性能的 HBM3E 样品,并将于 2024 年投入量产。
国内半导体公司对 HBM 的布局大多围绕着封装及接口领域。
国芯科技目前正在研究规划合封多 HBM 内存的 2.5D 的芯片封装技术,积极推进 Chiplet 技术的研发和应用。
通富微电公司 2.5D/3D 生产线建成后,将实现国内在 HBM 高性能封装技术领域的突破。
佰维存储已推出高性能内存芯片和内存模组,将保持对 HBM 技术的持续关注。
澜起科技 PCIe 5.0/CXL 2.0 Retimer 芯片实现量产,该芯片是澜起科技 PCIe 4.0 Retimer 产品的关键升级,可为业界提供稳定可靠的高带宽、低延迟 PCIe 5.0/ CXL 2.0 互连解决方案。
HBM 虽好但仍需冷静,HBM 现在依旧处于相对早期的阶段,其未来还有很长的一段路要走。而可预见的是,随着越来越多的厂商在 AI 和机器学习等领域不断发力,内存产品设计的复杂性正在快速上升,并对带宽提出了更高的要求,不断上升的宽带需求将持续驱动 HBM 发展。
HBM 火热反映了 AIGC 的带动能力。那么除了 HBM 和 GPU,是否还有别的产品在这波新风潮中能够顺势发展?
谈谈其他被带火的芯片
FPGA 的优势开始显现
FPGA(Field Programmable Gate Array,现场可编程门阵列)是一种集成电路,具有可编程的逻辑元件、存储器和互连资源。不同于 ASIC(专用集成电路),FPGA 具备灵活性、可定制性、并行处理能力、易于升级等优势。
通过编程,用户可以随时改变 FPGA 的应用场景,FPGA 可以模拟 CPU、GPU 等硬件的各种并行运算。因此,在业内也被称为「万能芯片」。
FPGA 对底层模型频繁变化的人工智能推理需求很有意义。FPGA 的可编程性超过了 FPGA 使用的典型经济性。需要明确的是,FPGA 不会成为使用数千个 GPU 的大规模人工智能系统的有力竞争对手,但随着人工智能进一步渗透到电子领域,FPGA 的应用范围将会扩大。
FPGA 相比 GPU 的优势在于更低的功耗和时延。GPU 无法很好地利用片上内存,需要频繁读取片外的 DRAM,因此功耗非常高。FPGA 可以灵活运用片上存储,因此功耗远低于 GPU。
6 月 27 日,AMD 宣布推出 AMD Versal Premium VP1902 自适应片上系统(SoC),是基于 FPGA 的自适应 SoC。这是一款仿真级、基于小芯片的设备,能够简化日益复杂的半导体设计的验证。据悉,AMD VP1902 将成为全球最大的 FPGA,对比上一代产品(Xilinx VU19P),新的 VP1902 增加了 Versal 功能,并采用了小芯片设计,使 FPGA 的关键性能增加了一倍以上。
东兴证券研报认为,FPGA 凭借其架构带来的时延和功耗优势,在 AI 推理中具有非常大的优势。浙商证券此前研报亦指出,除了 GPU 以外,CPU+FPGA 的方案也能够满足 AI 庞大的算力需求。
不同于 HBM 被海外公司垄断,国内公司 FPGA 芯片已经有所积累。
安路科技主营业务为 FPGA 芯片和专用 EDA 软件的研发、设计和销售,产品已广泛应用于工业控制、网络通信、消费电子等领域。紫光国微子公司紫光同创是专业的 FPGA 公司,设计和销售通用 FPGA 芯片。紫光国微曾在业绩说明会上表示,公司的 FPGA 芯片可以用于 AI 领域。东土科技主要开展 FPGA 芯片的产业化工作,公司参股公司中科亿海微团队自主开发了支撑其 FPGA 产品应用开发的 EDA 软件。
国产替代新思路:存算一体+Chiplet
能否利用我们现在可用的工艺和技术来开发在性能上可以跟英伟达对标的 AI 芯片呢?一些「新思路」出现了,例如存算一体+Chiplet。
存算分离会导致算力瓶颈。AI 技术的快速发展,使得算力需求呈爆炸式增长。在后摩尔时代,存储带宽制约了计算系统的有效带宽,系统算力增长步履维艰。例如,8 块 1080TI 从头训练 BERT 模型需 99 天。存算一体架构没有深度多层级存储的概念,所有的计算都放在存储器内实现,从而消除了因为存算异构带来的存储墙及相应的额外开销;存储墙的消除可大量减少数据搬运,不但提升了数据传输和处理速度,而且能效比得以数倍提升。
一方面,存算一体架构与传统架构处理器处理同等算力所需的功耗会降低;另一方面,存算一体的数据状态都是编译器可以感知的,因此编译效率很高,可以绕开传统架构的编译墙。
美国亚利桑那州立大学的学者于 2021 年发布了一种基于 Chiplet 的 IMC 架构基准测试仿真器 SIAM, 用于评估这种新型架构在 AI 大模型训练上的潜力。SIAM 集成了器件、电路、架构、片上网络 (NoC)、封装网络 (NoP) 和 DRAM 访问模型,以实现一种端到端的高性能计算系统。SIAM 在支持深度神经网络 (DNN) 方面具有可扩展性,可针对各种网络结构和配置进行定制。其研究团队通过使用 CIFAR-10、CIFAR-100 和 ImageNet 数据集对不同的先进 DNN 进行基准测试来展示 SIAM 的灵活性、可扩展性和仿真速度。据称,相对于英伟达 V100 和 T4 GPU, 通过 SIAM 获得的 chiplet +IMC 架构显示 ResNet-50 在 ImageNet 数据集上的能效分别提高了 130 和 72。
这意味着,存算一体 AI 芯片有希望借助 Chiplet 技术和 2.5D / 3D 堆叠封装技术实现异构集成,从而形成大型计算系统。存算一体 + Chiplet 组合似乎是一种可行的实现方式,据称亿铸科技正在这条路上探索,其第一代存算一体 AI 大算力商用芯片可实现单卡算力 500T 以上,功耗在 75W 以内。也许这将开启 AI 算力第二增长曲线的序幕。
结语
世界人工智能大会上,AMD CEO 苏姿丰表示,未来十年一定会出现一个大型计算超级周期,因此,目前正是一个成为技术供应商的好时机,同时也是与一些将会利用这些技术开发不同应用的客户合作的好时机。
没有人想要一个只有一个主导者的行业。大模型市场能否让芯片行业拥有新的市场格局,能否让新玩家出现?
「大模型市场对芯片行业带来了新的市场格局和机会。通过推动 AI 芯片的发展、促进云计算和数据中心市场的增长以及引发竞争格局变化,大模型的兴起为芯片行业带来了新的发展方向。
需要注意的是,芯片行业是一个高度竞争和技术密集的行业。进入该行业需要庞大的资金和技术资源,以满足复杂的制造和研发要求。尽管大模型市场为新玩家提供了机会,但他们需要克服技术、资金和市场等方面的挑战,才能在竞争激烈的芯片行业中获得成功。」Chatgpt 如是回应。








评论